
Clean’MT
Clean’MT – Projet PRONTO
Joe El-Hajj, Baptiste Garnier, Quentin Thubert, Mathéo Vignaud
Une situation problématique
Chaque résident de l’IMT Atlantique, campus de Brest, connaît cette situation : on va à la laverie, avec notre linge sale, et lorsqu’on arrive on trouve toutes les machines occupées. Ou pire, on revient deux heures plus tard pour découvrir que la machine s’est arrêtée depuis longtemps et que son linge attend, froissé, dans le tambour.
C’est cette situation, partagé par les autres étudiants, que le groupe 81 du projet PRONTO a décidé d’essayer de résoudre, avec une contrainte forte posée dès le départ : n’apporter aucune modification permanente aux machines.
Notre solution
L’idée est simple : équiper chaque machine d’un petit boîtier connecté capable de détecter si elle tourne ou non, quel programme a été lancé, et combien de temps il reste — le tout accessible depuis son téléphone ou son ordinateur, sans avoir à bouger de sa chambre.
Pour y arriver, on a combiné deux types de capteurs. Le premier détecte les vibrations de la machine : quand le tambour tourne, ça vibre. Le second lit la position de la molette de sélection grâce à un aimant glissé dans un petit cache imprimé en 3D, qui s’emboîte sur la molette sans la modifier. Un magnétomètre placé juste au-dessus mesure le champ magnétique de l’aimant et en déduit le programme choisi.
Comment on a fait
Un boîtier et une arche
Tout le système est contenu dans deux pièces fabriquées au FabLab du campus, imprimées en 3D en PLA blanc. La première est un boîtier rectangulaire fixé sur le côté de la machine, qui abrite l’électronique. La seconde est une arche en U positionnée au-dessus de la molette, qui maintient le magnétomètre en place.
Détecter si la machine tourne
Le capteur de vibrations est glissé à l’intérieur du boîtier, bien plaqué contre le flanc de la machine. Quand le tambour est en marche, les vibrations se transmettent à travers la paroi et le capteur les enregistre.

Photo vue du dessus du capteur de vibration dans le boitier sur le flanc de la machine
Savoir quel programme a été choisi
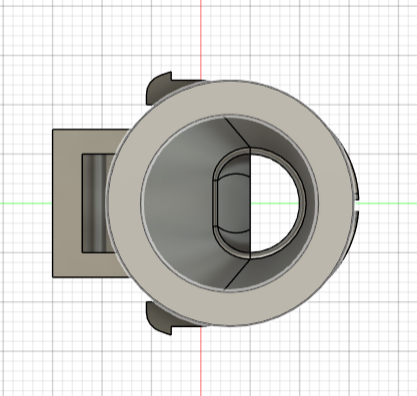
Comme on ne pouvait pas toucher à l’électronique interne de la machine, on a observé ce qui était accessible depuis l’extérieur : la molette. Elle tourne d’un cran à chaque programme, et chaque cran représente exactement le même angle. En fixant un petit aimant dans un cache qui s’emboîte par-dessus la molette originale, l’aimant tourne avec elle. Le magnétomètre, positionné juste au-dessus dans l’arche, mesure en permanence la direction du champ magnétique de cet aimant et en déduit l’angle de la molette, donc le programme sélectionné.
Quand l’utilisateur appuie sur la molette pour confirmer son choix, l’aimant s’éloigne légèrement du capteur grâce à un petit mécanisme à ressort intégré dans le cache. Cette chute du signal magnétique est immédiatement détectée, c’est comme ça que le système sait que le programme a bien été validé.

Photo du capteur de vibration et de la molette avec l’aimant intégré
Le cerveau du système : l’ESP32
Tous ces capteurs sont branchés à un microcontrôleur ESP32, une petite carte électronique pas plus grande qu’une carte de crédit, qui fait le lien entre les capteurs et internet. C’est lui qui analyse les données, décide si la machine est libre ou occupée, calcule le temps restant, et envoie tout ça vers une Raspberry Pi ou un ordinateur, pour les tests, grâce à BLE. Le serveur reçoit ainsi les infos pour mettre à jour le site via le Wi-Fi du campus depuis la Raspberry Pi.

Photo du montage global relié à un ordinateur
Le site web
Les informations remontent en temps réel vers cleanmt.fr. D’un coup d’œil, on voit quelles machines sont libres, lesquelles tournent, et combien de temps il reste. Une notification est envoyée dès que le cycle se termine pour récupérer son linge avant que celui ci ne gène les autres utilisateurs.

Image de la page principal du site internet
Le site propose aussi quelques extras : signaler du linge oublié, remonter une panne à la maintenance, ou consulter l’historique des créneaux les moins chargés pour mieux planifier ses lessives.
Et maintenant ?
Clean’MT est aujourd’hui un prototype qui fonctionne, conçu en quelques mois par quatre étudiants avec moins de 40 € de matériel. Mais surtout, c’est une solution concrète à un problème que vivent des centaines de personnes chaque semaine. L’ambition est d’aller plus loin : déployer le système sur toutes les machines de la laverie et pérenniser le service via une association étudiante, pour que le projet survive bien au-delà de cette année. Parce qu’une bonne idée ne devrait pas s’arrêter à la soutenance.
BREIZH4LINE – Solutions techniques
Nom de l’équipe : BREIZH4LINE
Membres de l’équipe :
Axelle Mellier, FISE A2 IMT Atlantique
Jean-Louis Dje, FISE A2 IMT Atlantique
Lise Pelletier, FISE A2 IMT Atlantique
Romain Christol, FISE A2 IMT Atlantique
Samuel Pooda, FISE A2 IMT Atlantique
I – CONTEXTE
Cet article s’inscrit dans le cadre du Projet Fil Rouge de la TAF COUAD. L’objectif de ce projet est de partir d’une problématique réelle et locale, de la formaliser, puis de concevoir et de mettre en œuvre une solution technique adaptée.
Cela dit, notre équipe a choisi de s’intéresser au gaspillage de l’eau dans les ménages et aux conséquences environnementales associées, notamment le risque de pénurie d’eau dans certaines localités françaises. À partir de ce constat, nous avons conçu une solution technique visant à mesurer, centraliser et exploiter les données de consommation d’eau domestique.
Ainsi, la solution repose sur quatre composantes centrales, chacune ayant un rôle bien défini :
- un capteur de volume d’eau consommée par utilisation, fixé directement sur un robinet

- un afficheur, placé à proximité du robinet, permettant de visualiser localement les données mesurées

- un serveur web local, chargé de centraliser l’ensemble des données de consommation sans recours à Internet

- une application web, hébergée sur ce serveur, offrant une interface de gestion détaillée de la consommation d’eau

Par conséquent, l’application web permet plusieurs fonctionnalités essentielles : la visualisation des données en temps réel, la consultation des coûts financiers associés à la consommation, ainsi que l’accès à des recommandations personnalisées visant à améliorer les habitudes de consommation à partir des données personnelles collectées
De plus, l’ensemble des composantes du système communique entre elles selon un schéma de communication bien précis. Le capteur mesure le volume d’eau utilisé et transmet ces données aux autres éléments du système. L’afficheur reçoit ces informations afin de les présenter immédiatement à l’utilisateur, tandis que le serveur web local joue le rôle de point central : il collecte, stocke et met à disposition les données pour l’application web. Cette organisation permet un fonctionnement autonome, sans dépendance à une connexion Internet.
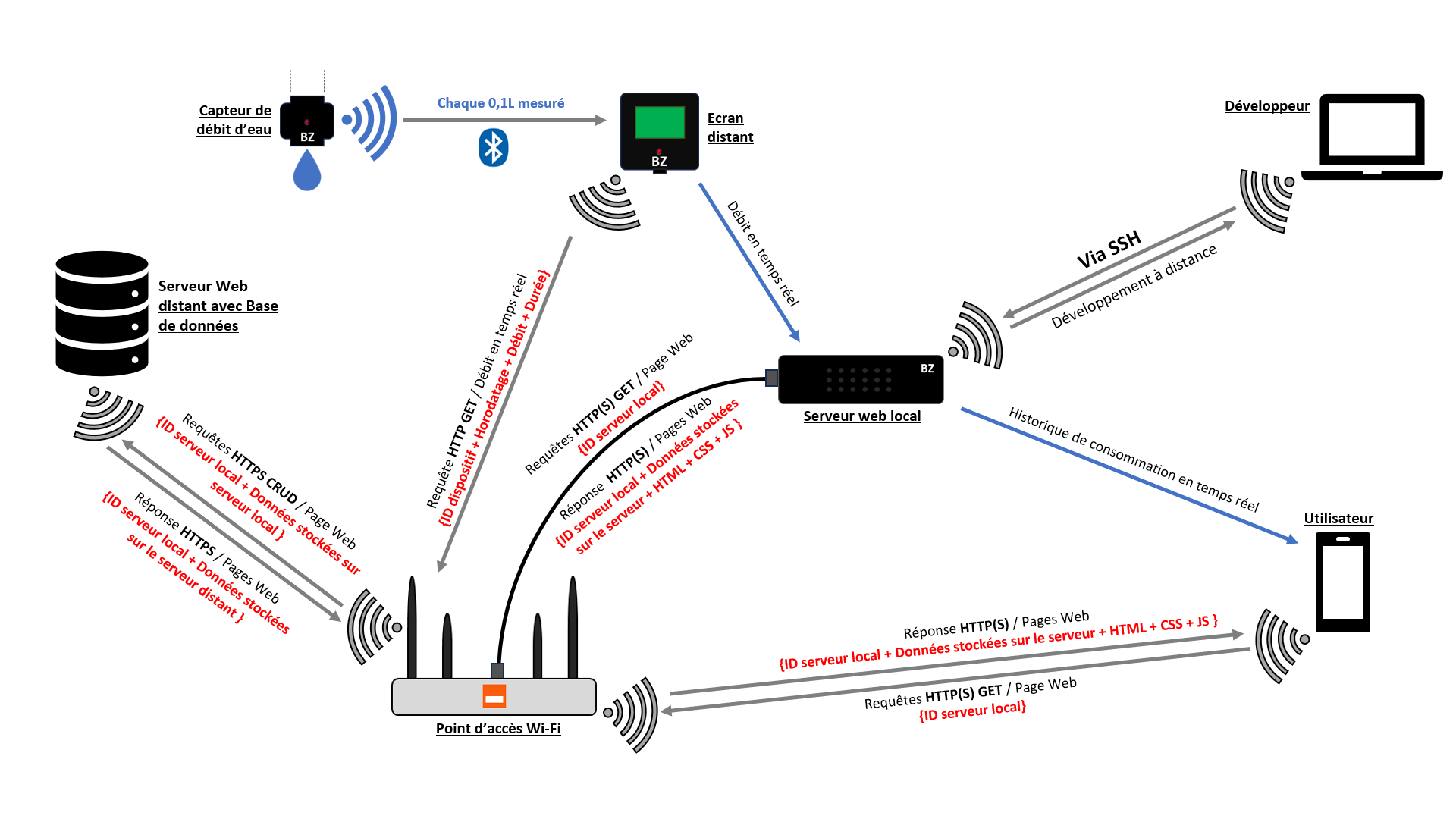
Par ailleurs, la solution est structurée autour de deux grandes approches complémentaires. D’une part, les composantes matérielles regroupent la conception électronique ainsi que la modélisation et l’impression 3D des éléments physiques, à savoir le serveur, le capteur et l’afficheur. D’autre part, les composantes logicielles concernent l’ensemble de la plateforme web développée pour l’exploitation des données.
En outre, la réalisation d’un premier prototype a nécessité l’ensemble du matériel suivant :
- une (1) Raspberry Pi 3B+
- deux (2) cartes ESP32
- deux (2) modules Bluetooth HC-05
- un (1) élévateur de tension U3V40F5
- un (1) afficheur 7 segments 4 digits TM1637
- une (1) batterie lithium 3.7v 2200mAh
- un (1) débitmètre commercial Titan
- un (1) module de charge de batterie
- un (1) interrupteur
- des câbles
Enfin, toutes les pièces physiques utilisées dans ce tutoriel ont été modélisées à l’aide du logiciel Fusion 360, puis exportées au format .stl afin d’être imprimées en 3D. Le traitement de ces fichiers a été réalisé avec le logiciel Ultimaker Cura, permettant de vérifier la faisabilité des impressions, d’optimiser l’orientation des pièces et d’ajouter, si nécessaire, des supports pour garantir une impression correcte.
II – SERVEUR
Le serveur local de notre solution repose sur une Raspberry Pi 3B+, sur laquelle est déployé un serveur web hébergeant notre application web de gestion de la consommation d’eau.
La mise en œuvre de ce serveur s’articule autour de deux éléments clés. Il s’agit notamment de la carte Raspberry Pi, de son support physique ainsi que des composants électroniques associés.
1 – Raspberry Pi
Premièrement, la carte Raspberry Pi 3B+, qui est un micro-ordinateur monocarte (single-board computer). Compacte et peu coûteuse, elle intègre un processeur ARM, de la mémoire vive (RAM), des interfaces réseau filaires et sans fil (Ethernet et Wi-Fi) ainsi que divers ports d’entrées/sorties, lui permettant d’exécuter un système d’exploitation et des applications serveur.

Cette carte, que nous appellerons RPI dans la suite de ce tutoriel, dispose donc de ressources suffisantes pour héberger un serveur web et le rendre accessible sur un réseau local, créé à partir d’un point d’accès Wi-Fi partagé entre l’Afficheur et nos terminaux mobiles.
Dans notre configuration, la RPI émule son propre point d’accès Wi-Fi, ce qui permet de s’affranchir de l’utilisation d’une box Internet ou d’un point d’accès mobile externe. Nous avions initialement opté pour cette solution ; cependant, après plusieurs jours de développement, ce point d’accès s’est révélé instable, puis inutilisable. Néanmoins, lorsqu’elle est correctement configurée et maîtrisée, cette approche demeure l’une des meilleures alternatives dans un contexte autonome.
Afin de permettre les échanges de données entre l’Afficheur et le serveur local, mais également l’accès à l’application web hébergée, il était indispensable de relier l’ensemble des composants par un support de communication commun. Le support retenu est le Wi-Fi.
Ce choix s’explique, dans un premier temps, par la nécessité d’utiliser le protocole HTTP, indispensable à l’accès à une application web. HTTP est en effet le protocole standard des communications web, reposant principalement sur une architecture client–serveur, et il s’appuie sur des réseaux IP, dont le Wi-Fi constitue un moyen d’accès courant.
Dans un second temps, le Wi-Fi permet également d’assurer la communication entre l’Afficheur, qui héberge un client web, et le serveur web. Bien que le volume d’eau mesuré par le capteur, puis relayé à l’Afficheur, aurait pu être transmis au serveur via d’autres technologies de communication telles que le Bluetooth, l’utilisation de plusieurs canaux distincts aurait été inutilement complexe. Le Wi-Fi, déjà employé pour l’accès à l’application web, s’est donc imposé comme une solution unique et cohérente.
Notre application web nécessitant le stockage de données structurées — notamment les données personnelles des utilisateurs sous forme de textes et de valeurs numériques, ainsi que l’ensemble des informations requises par les différentes fonctionnalités — nous avons implémenté une base de données sur le serveur. Nous avons opté pour une base de données relationnelle de type SQL, en l’occurrence MariaDB. MariaDB étant facile à déployer sur notre RPI grâce à des bibliothèques existantes et compatibles avec le système d’exploitation.
La mise en œuvre de la base de données et du serveur web sur la RPI s’est déroulée comme décrit ci-dessous.
Pour tout le tutoriel, nous utiliserons le terminal de la Raspberry Pi via SSH, sauf indication contraire.
SSH (Secure Shell) est un protocole de communication sécurisé qui permet d’accéder à distance à la ligne de commande d’un autre ordinateur à travers un réseau, tout en chiffrant les échanges afin de garantir la confidentialité et l’intégrité des données.
Bien qu’il soit parfois plus simple d’utiliser l’interface graphique, l’usage du terminal via SSH présente l’avantage de pouvoir administrer la RPI sans écran, clavier ni souris, évitant ainsi de devoir transporter du matériel supplémentaire.
2 – Support physique

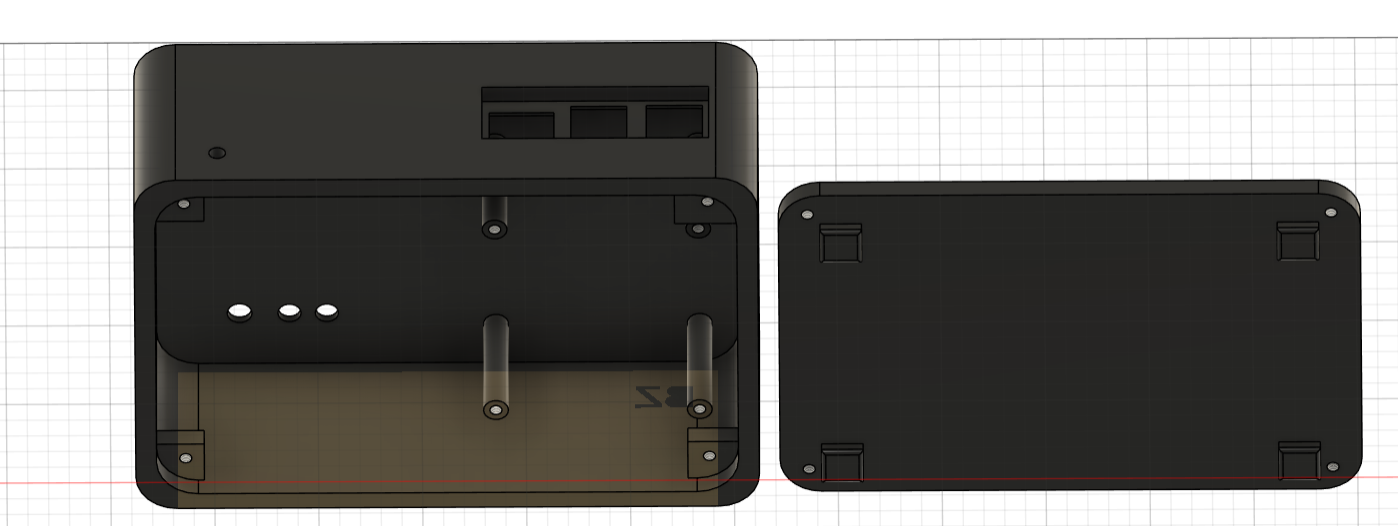
Le support physique prend la forme d’un boîtier comportant, à l’arrière, des orifices permettant l’accès aux ports physiques de la Raspberry Pi. À ce boîtier est associé un couvercle faisant également office de support au sol, assurant la stabilité de l’ensemble du serveur.
Le serveur présente un volume approximatif de 150 × 104 × 50 mm.
Des cylindres solidaires du boîtier, visibles sur la dernière image, permettent de fixer la RPI.

III – AFFICHEUR
L’Afficheur est la composante du système qui permet de visualiser, en temps quasi réel, le volume d’eau mesuré par le capteur. Il est installé à proximité du capteur et assure un rôle d’interface entre celui-ci et le serveur local.
L’Afficheur est connecté au capteur via Bluetooth et au serveur local via Wi-Fi.
Concernant la communication entre l’Afficheur et le capteur, nous avons opté pour le Bluetooth, car cette technologie est particulièrement adaptée aux communications de courte portée, sans obstacle majeur, tout en offrant une connexion active et stable entre les deux dispositifs.
Ce choix est également motivé par nos perspectives d’évolution : le capteur pourrait, à terme, être intégré à un pommeau de douche. Dans ce contexte, une éventuelle chute ou manipulation du capteur ne devrait pas entraîner de rupture de la communication. Le Bluetooth présente ainsi une bonne robustesse, une faible consommation énergétique et une portée suffisante pour ce type d’usage.
Nous avons donc privilégié cette solution, peu coûteuse en énergie, adaptée à la distance et fiable, au détriment d’autres technologies telles que le Wi-Fi ou l’infrarouge. En effet, bien que le Wi-Fi soit déjà utilisé par l’Afficheur pour communiquer avec le serveur local, son utilisation pour la communication avec le capteur aurait nécessité la mise en place d’un serveur sur l’un des deux dispositifs, impliquant une complexité logicielle supplémentaire incompatible avec les objectifs de simplicité et de robustesse de notre projet.
La mise en œuvre de l’Afficheur repose sur trois éléments principaux : le réceptacle contenant l’électronique, l’électronique embarquée elle-même, et le programme implémenté sur la carte programmable.
1 – Électronique
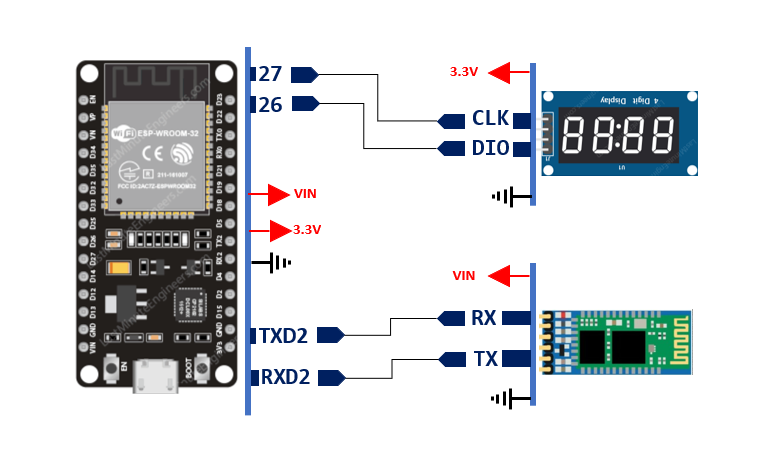
L’Afficheur est basé sur une carte programmable ESP32, un microcontrôleur 32 bits développé par Espressif Systems. L’ESP32 intègre un processeur double cœur, de la mémoire, ainsi que des interfaces de communication natives telles que le Wi-Fi, le Bluetooth et plusieurs bus de communication (UART, SPI, I²C). Ces caractéristiques en font une solution particulièrement adaptée aux systèmes embarqués connectés, offrant une faible consommation énergétique et une grande flexibilité pour le développement.

Bien que l’ESP32 intègre nativement le Bluetooth, nous avons choisi d’ajouter un module Bluetooth HC-05 externe. Cette décision est motivée par le fait que l’utilisation simultanée du Wi-Fi et du Bluetooth sur l’ESP32 n’est pas optimale pour notre projet : la carte utilise la même antenne pour les deux types de communication, ce qui peut provoquer des interférences et rendre les échanges moins fiables, en particulier dans un système nécessitant un temps réel quasi instantané. L’utilisation du HC-05 externe nous permet ainsi de séparer les flux Bluetooth et Wi-Fi, garantissant stabilité et fiabilité de la communication avec le capteur et le serveur.
Le module HC-05 est un module Bluetooth classique (Bluetooth 2.0 + EDR) fonctionnant en mode maître ou esclave, largement utilisé pour sa simplicité d’intégration, sa stabilité et son faible coût. Il communique avec l’ESP32 via le protocole UART (Universal Asynchronous Receiver/Transmitter), un protocole série asynchrone permettant l’échange de données bit par bit entre l’émetteur et le récepteur sans signal d’horloge partagé. L’UART est fiable, simple à mettre en œuvre et adapté aux communications avec des périphériques embarqués.

L’Afficheur intègre également un afficheur 7 segments à 4 digits, le TM1637 de la gamme Grove. Ce module permet d’afficher des valeurs numériques de manière lisible et claire, et communique avec le microcontrôleur via une interface série à deux fils (CLK et DIO), ce qui simplifie le câblage et limite l’usage de broches.
Le logiciel de l’Afficheur suit le cycle suivant :
- Réception du volume d’eau via Bluetooth : le HC-05 reçoit en continu les mesures envoyées par le capteur et les transmet à l’ESP32 via UART.
- Traitement des données : l’ESP32 convertit et formate les valeurs reçues pour l’affichage, gère les éventuelles erreurs de transmission et met à jour les variables internes.
- Affichage sur le TM1637 : les données traitées sont envoyées à l’afficheur 7 segments pour une visualisation en temps quasi réel.
- Transmission au serveur via Wi-Fi : simultanément, l’ESP32 envoie les valeurs reçues au serveur local via Wi-Fi, permettant leur enregistrement dans la base de données et leur consultation via l’application web.
Cette architecture logicielle garantit que les mesures sont affichées et transmises au serveur de manière fluide et fiable, tout en séparant les communications Bluetooth (capteur → Afficheur) et Wi-Fi (Afficheur → serveur) pour éviter les interférences.
2 – Support physique
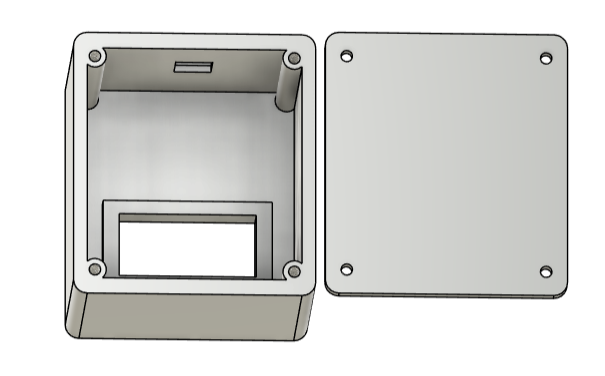
Le support physique de l’Afficheur présente un volume approximatif de 53 × 47 × 40 mm. Il est constitué d’un boîtier et d’un couvercle, chacun percé de trous permettant de les fixer ensemble à l’aide de vis.
Enfin, l’avant du boîtier comporte une cavité rectangulaire dans laquelle l’afficheur TM1637 vient se loger, garantissant une installation stable et sécurisée de la partie visible du dispositif.
3 – Programme : Code Arduino
Le code de l’afficheur se trouve sur le Github dont le lien suit : https://github.com/Jean-Louis-DJE/brz-fil-rouge.git
IV – CAPTEUR
Le Capteur est la composante du système que nous avons conçue pour être fixée directement sur un robinet, à la sortie du jet d’eau. Il s’agit d’un débitmètre auquel nous avons ajouté des fonctions de communication et de calcul afin de mesurer le volume d’eau écoulé et de transmettre cette information aux autres éléments du système.
Nous avons choisi d’utiliser un débitmètre commercial pour la version finale du projet. Le modèle retenu est un débitmètre de l’entreprise Titan, initialement conçu pour la mesure de boissons comestibles. Ce choix s’est révélé pertinent, mais il a imposé certaines contraintes d’intégration qui ont conduit à modifier les dimensions prévues pour le Capteur.

En effet, ce débitmètre nécessite une stabilité de l’écoulement du liquide afin de fournir des mesures fiables. Pour cela, le guide d’utilisation recommande d’ajouter, de chaque côté du débitmètre, un tuyau dont la longueur est égale à dix fois le diamètre d’un de ses orifices, afin de stabiliser le flux d’eau.
Par ailleurs, le débitmètre fonctionne à l’aide d’un capteur à effet Hall, qui permet de mesurer le débit en détectant la rotation d’un élément interne soumis à un champ magnétique. Pour limiter les risques d’interférences magnétiques, nous avons choisi de ne pas sectionner les câbles d’alimentation et de données, dont la longueur dépasse un mètre, bien que des calculs plus précis auraient pu permettre de les raccourcir.
Ainsi, nous avons suivi les recommandations du fabricant concernant le câblage et l’utilisation du débitmètre. Cela nous a conduits à séparer physiquement le débitmètre du reste de l’électronique. Nous avons néanmoins modélisé et imprimé un réceptacle destiné à contenir les composants électroniques, sans détailler ce boîtier dans ce tutoriel.
Ensuite, le débitmètre a été connecté à une carte programmable ESP32, à laquelle nous avons ajouté un module Bluetooth HC-05 externe. Bien que l’ESP32 intègre nativement le Bluetooth, nous avons fait ce choix afin de tester différents scénarios de communication, et nous avons conservé cette configuration jusqu’à la version finale du projet.
De plus, le Capteur est alimenté par une batterie Li-Po de 3,7 V et 2200 mAh, ce qui lui permet de fonctionner de manière autonome.

Comme le module Bluetooth nécessite une tension comprise entre 3,6 V et 6 V, nous avons intégré un élévateur de tension U3V40F5 du fabricant Pololu afin d’adapter la tension fournie par la batterie.


Cependant, cet élévateur de tension ne dispose pas de circuit de charge intégré pour la batterie. Nous avons donc utilisé un module de charge externe pour batterie Li-Po, équipé d’un port Micro-USB, afin de permettre la recharge de la batterie en toute sécurité même avec un adaptateur de téléphone.

Finalement, le Capteur se compose de deux parties principales : l’électronique, qui regroupe le débitmètre, la carte programmable, le module Bluetooth et le système d’alimentation, et le programme embarqué, qui est exécuté sur la carte programmable.
1 – Schéma électronique 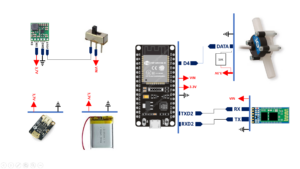
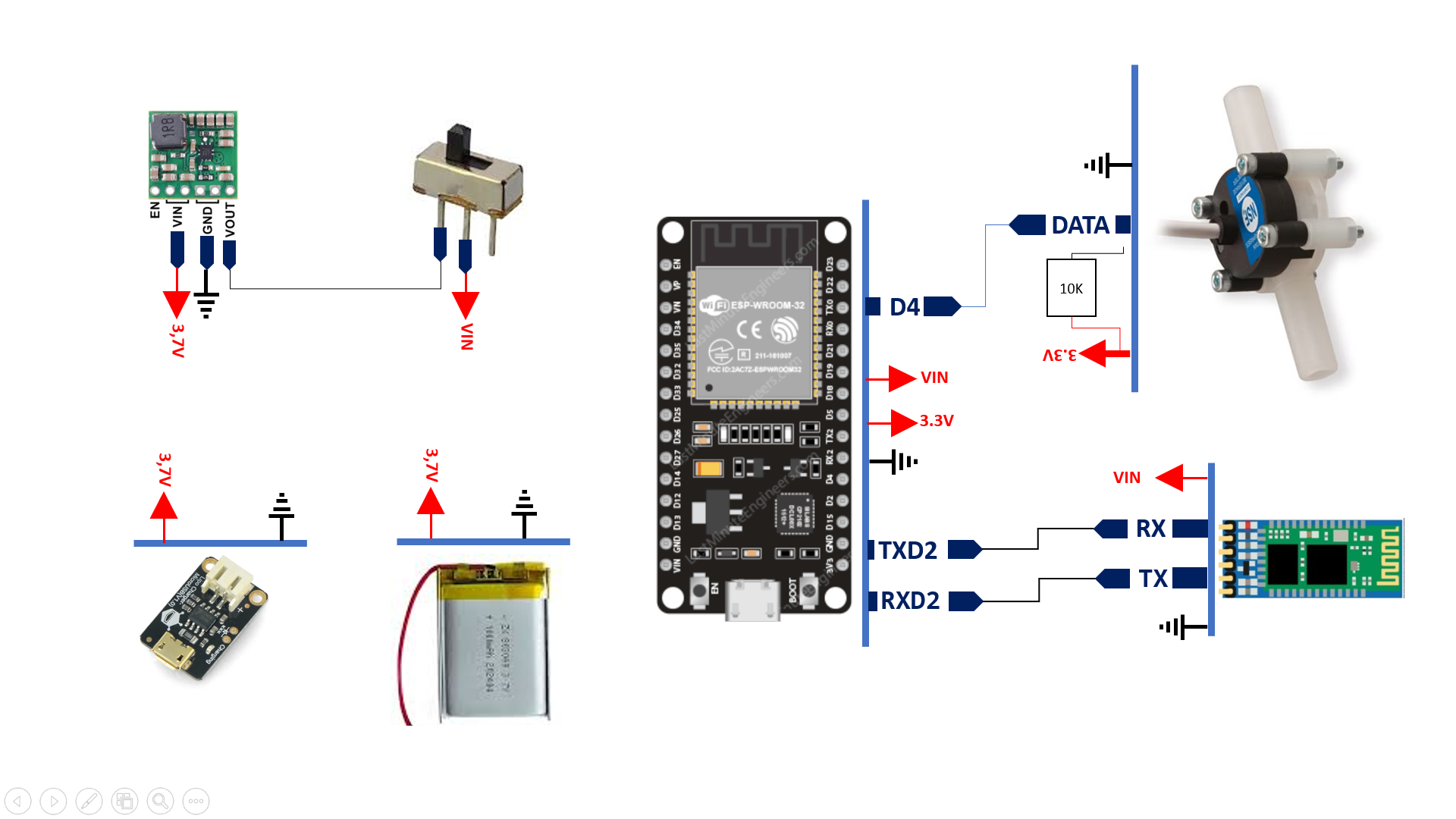
NB : veillez à mettre une résistance de pull-up sur DATA. L’interrupteur permet de mettre l’élévateur hors tension lorsque nous voulons programmer la carte afin d’éviter qu’un courant le traverse dans le sens inverse – de la sortie VOUT vers son circuit –. Ce modèle n’est pas équipé d’une protection de courant inverse.
2 – Programme
Le code du Capteur se trouve sur le Github dont le lien suit : https://github.com/Jean-Louis-DJE/brz-fil-rouge.git
V – COMPOSANTES LOGICIELLES
1 – Interfaces graphiques
A. Maquette
Nous avons tout d’abord réalisé une maquette de l’application car elle permet de visualiser, avant même d’écrire une ligne de code, l’organisation des informations, la navigation entre les écrans et l’expérience utilisateur et d’anticiper les contraintes techniques (taille de l’écran, fréquence des mises à jour, lisibilité des mesures en temps réel) et de réduire le temps de développement en validant l’ergonomie en amont.
Pour cela, nous avons utilisé Figma, un outil de prototypage moderne, car il permet de créer des interfaces rapidement, d’obtenir un rendu réaliste et de partager les écrans facilement entre les membres de l’équipe.
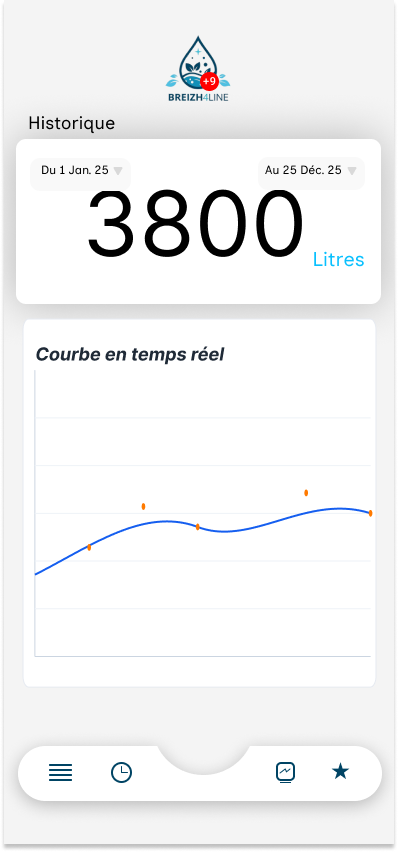
B. Interface finale
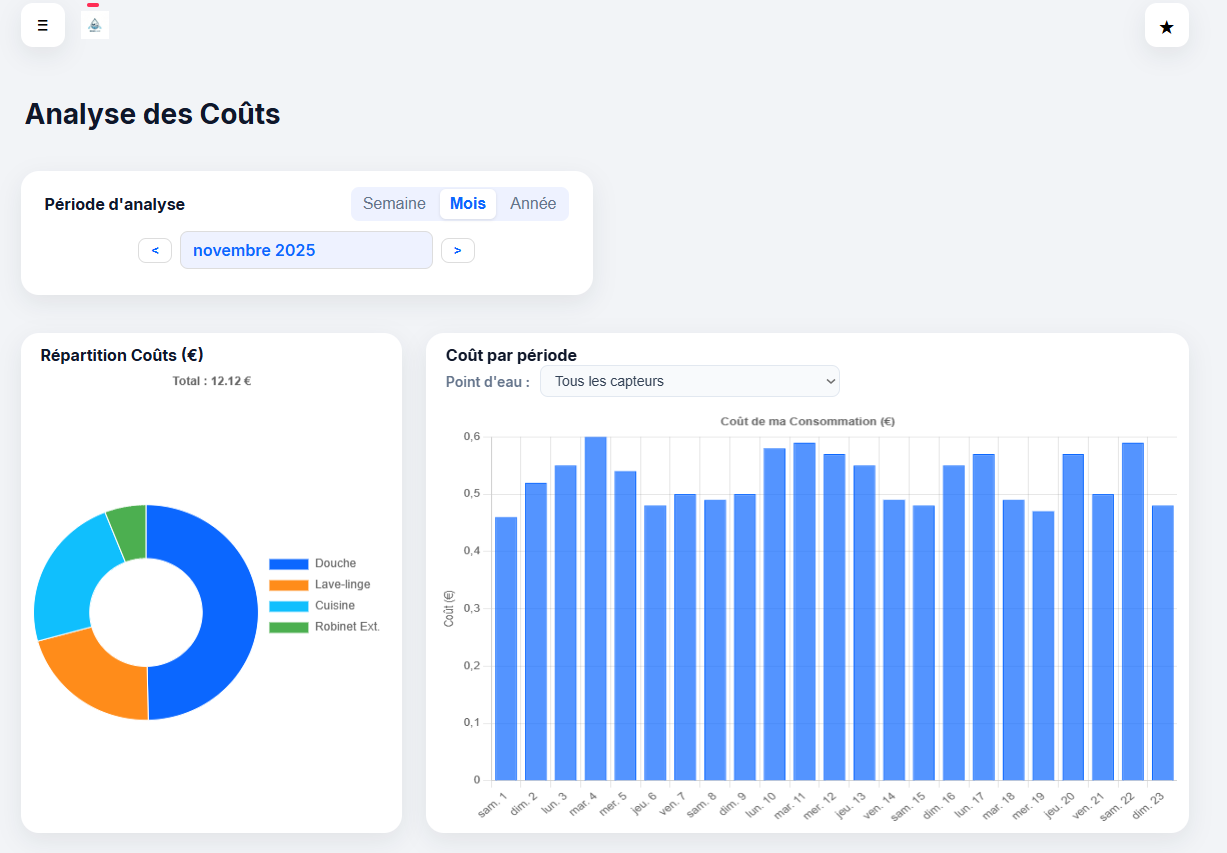
Après plusieurs discussions et modifications, nous nous sommes arrêtés sur cette version finale de l’interface :
- Le menu permettant d’accéder aux différents onglets de l’application
- Le compteur principal affichant le volume consommé total du foyer sur une période souhaitée
- Un dashboard pour consulter les consommations des différents points d’eau sur une période souhaitée
- Un dashboard pour consulter les coûts associés aux consommations des différents points d’eau sur une période souhaitée
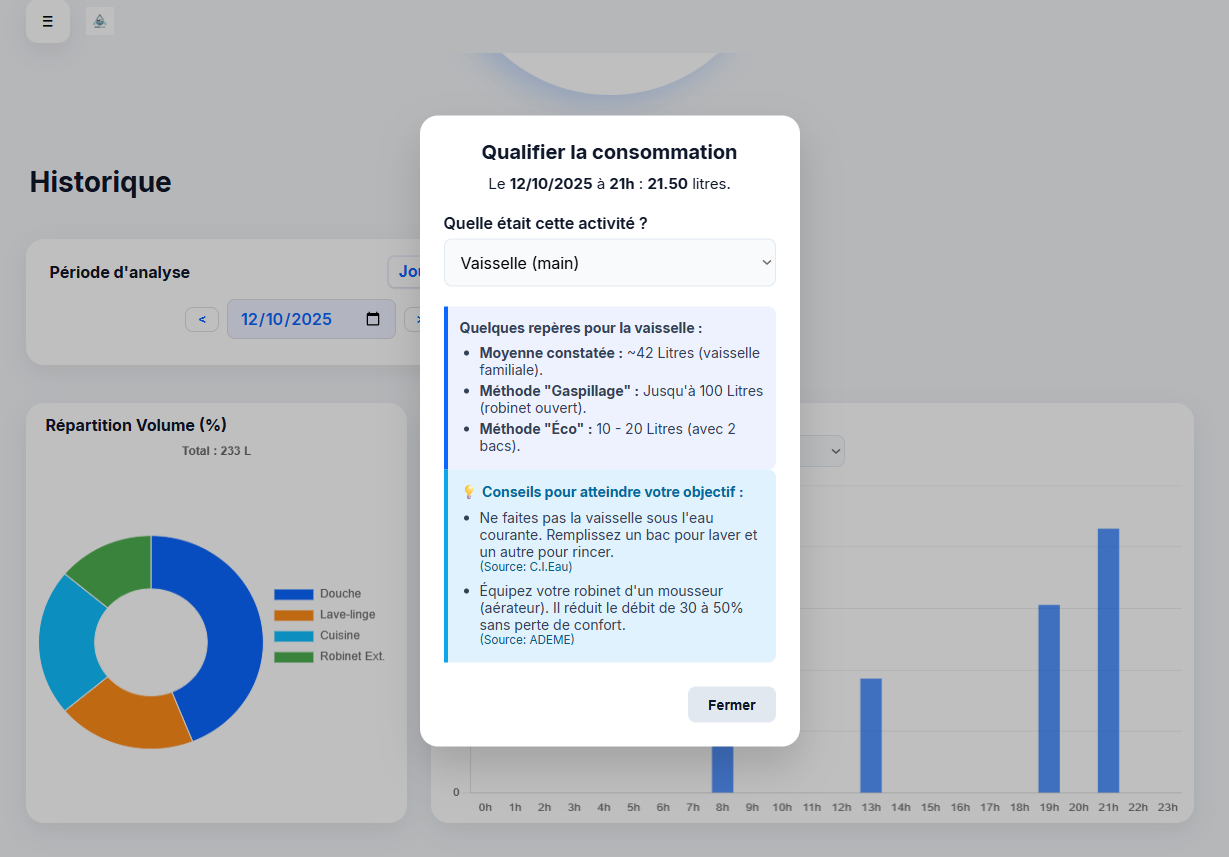
- Des conseils et recommandations lorsque l’utilisateur se fixe un objectif
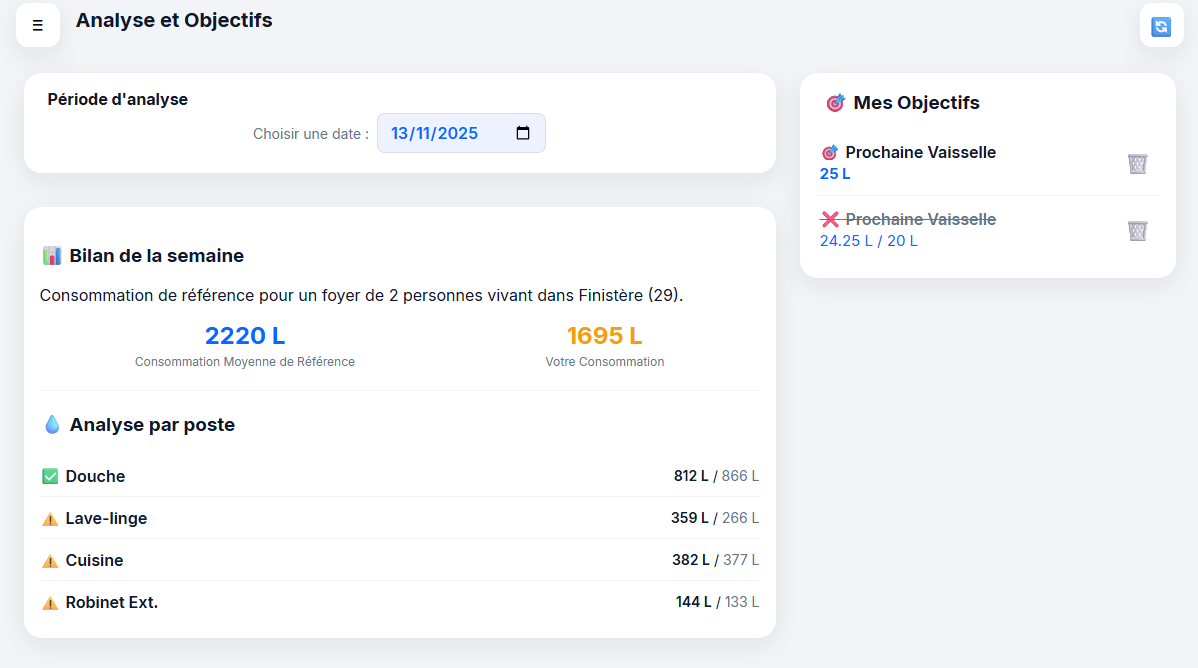
- Un dashboard permettant d’avoir une analyse de la consommation du foyer (par rapport à des données moyennes de référence) et de consulter les objectifs que l’utilisateur s’est fixé
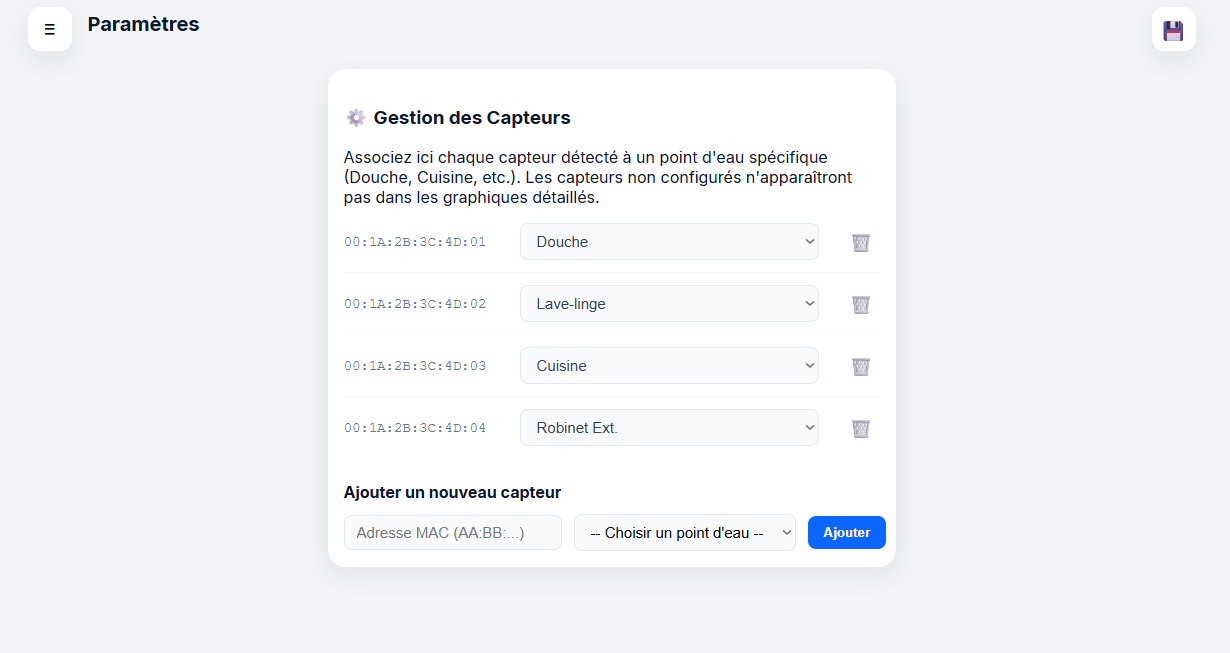
- Une interface permettant d’associer un capteur au point d’eau qu’il analyse
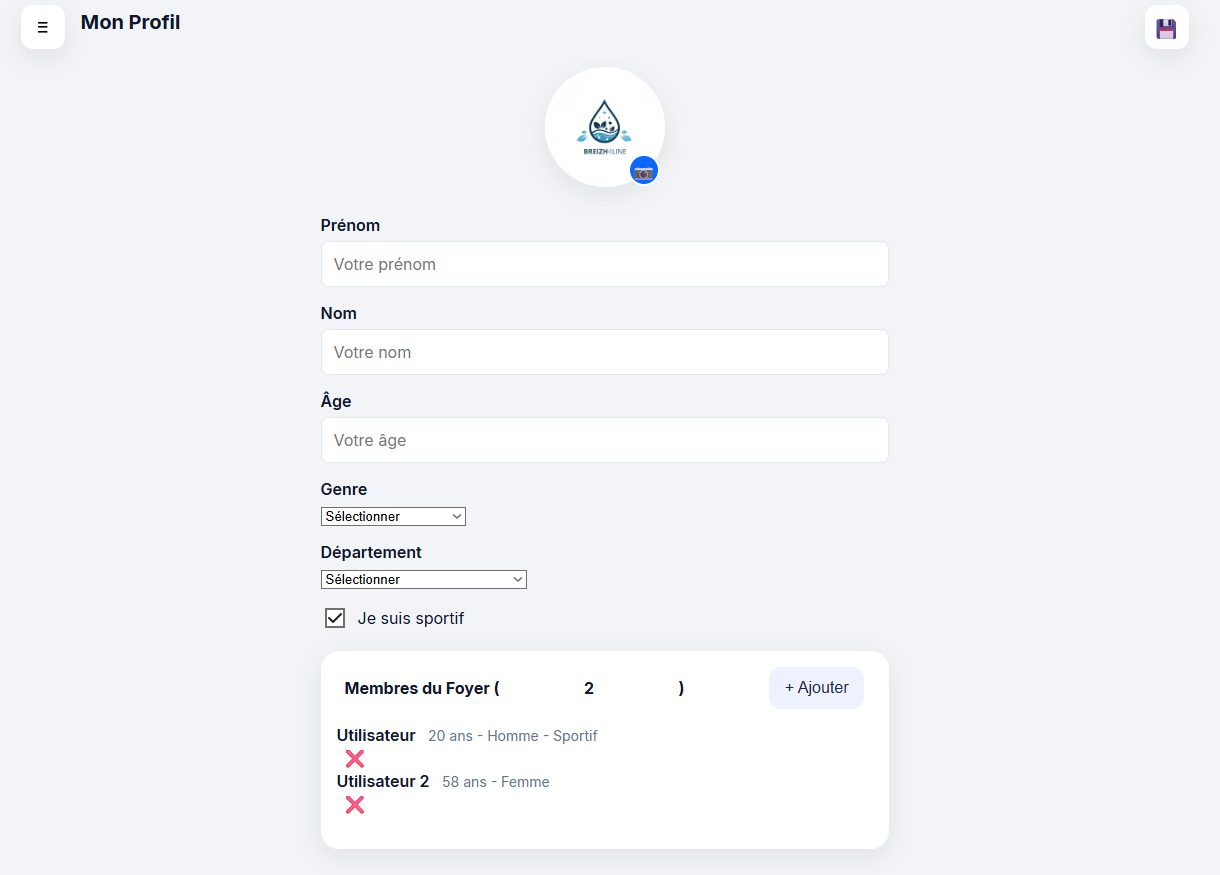
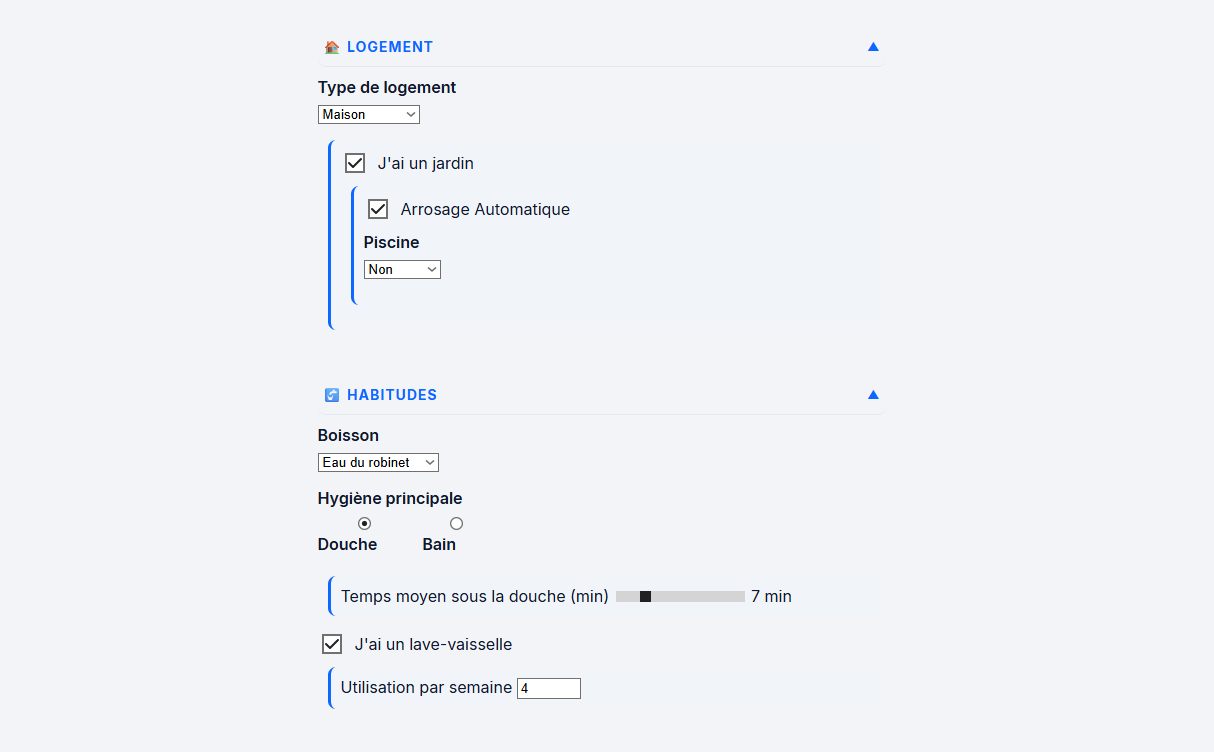
- Une section profil pour que l’utilisateur renseigne des informations sur son foyer afin que les analyses soient adaptées à ce dernier
2 – Base de données
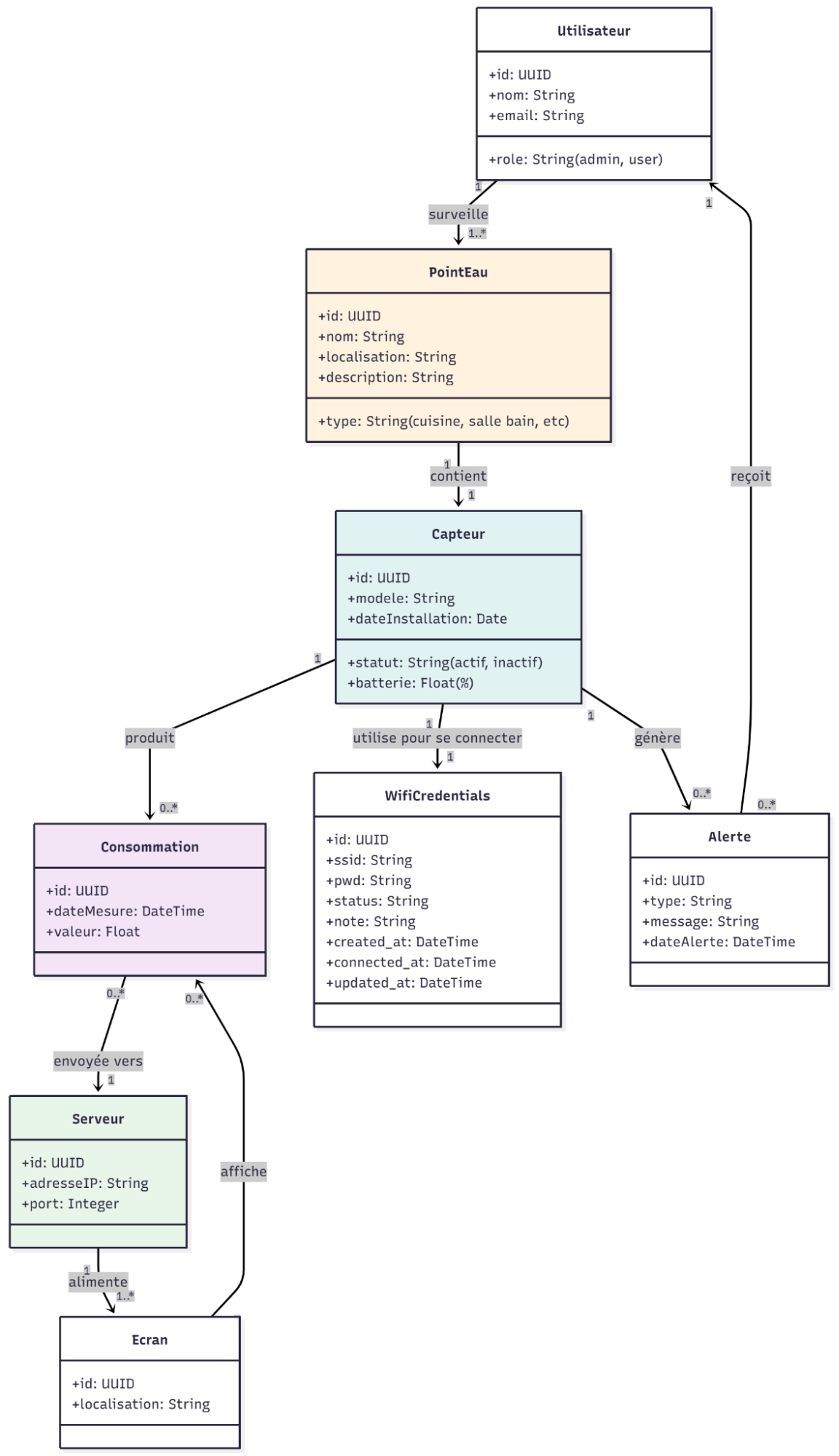
Ce diagramme UML correspond au modèle de départ du projet. Il a été conçu en début de conception afin de structurer le système et d’identifier les principales entités : utilisateur, points d’eau, capteurs, consommations, alertes, serveur et interfaces d’affichage.
Ce modèle nous a permis de poser une vision globale du fonctionnement du système, en distinguant clairement les données métier (consommation, alertes), les composants techniques (capteur, serveur, Wi-Fi) et l’interface utilisateur.
Au cours du projet, ce diagramme a ensuite été ajusté afin de mieux correspondre aux usages réels et à l’approche low-tech retenue. Certains choix ont été simplifiés, notamment sur la gestion des utilisateurs ou des composants, afin de réduire la complexité, faciliter l’installation par un utilisateur non expert et améliorer la maintenabilité du système.
Ce travail itératif illustre une démarche de conception réaliste : partir d’un modèle complet, puis faire des choix techniques raisonnés en fonction des contraintes du projet et des objectifs finaux.
Le modèle conceptuel de données a été conçu pour rester simple, cohérent et adapté à un usage local, tout en permettant une évolution future du système.
- Séparation des données métier et techniques
Les entités Consommation, PointEau et Alerte représentent le cœur métier du projet. À l’inverse, WifiCredentials concerne uniquement la configuration réseau du dispositif. Cette séparation permet d’éviter les dépendances inutiles et améliore la maintenabilité du système. - Lien direct entre point d’eau et capteur
Chaque point d’eau est associé à un seul capteur afin de garantir la traçabilité des mesures et d’éviter toute ambiguïté dans l’origine des données. Ce choix simplifie également l’installation et le déploiement du dispositif. - Historique détaillé des consommations
La table Consommation permet de stocker chaque mesure avec un horodatage précis. Ce choix est essentiel pour fournir un historique exploitable, générer des statistiques et déclencher des alertes basées sur l’usage réel. - Gestion des alertes indépendante
Les alertes sont modélisées comme une entité distincte afin de ne pas surcharger les données de consommation. Cela permet de gérer différents types d’anomalies (surconsommation, fuite) et d’adapter les règles de détection sans modifier le reste du modèle. - Présence de l’entité Utilisateur dans le modèle initial
L’entité Utilisateur a été intégrée dans la version initiale du MCD afin d’anticiper une éventuelle évolution vers un système multi-utilisateurs. Par la suite, certains scénarios ont été simplifiés pour correspondre à un usage domestique sans authentification.
Dans l’ensemble, ce MCD reflète une approche pragmatique et évolutive, où les choix ont été guidés par les contraintes du terrain, l’objectif low-tech du projet et la volonté de proposer un système compréhensible et facile à maintenir.
3 – Architecture logicielle

L’architecture logicielle du système repose sur une approche modulaire et distribuée, adaptée à un contexte IoT et à une utilisation locale sans dépendance à Internet.
Le capteur de débit, associé à un microcontrôleur, mesure la consommation d’eau et transmet les valeurs au boîtier afficheur via une communication Bluetooth. Ce choix permet de séparer physiquement le point de mesure du point d’affichage, tout en conservant une communication simple et à faible consommation.
Le boîtier afficheur, basé sur un ESP32, joue le rôle de passerelle logicielle. Il reçoit les données du capteur, les affiche en temps réel pour l’utilisateur, puis les transmet au serveur local via une API REST HTTP grâce à une connexion Wi-Fi. Cette passerelle centralise ainsi l’affichage, la communication réseau et la transmission des données.
Le serveur local assure le stockage des informations dans une base de données locale. Il expose également une API REST permettant à l’application web de récupérer les données via des requêtes GET, sans accès direct à la base de données depuis les équipements embarqués.
Enfin, l’application web se connecte au serveur local pour charger et afficher les informations de consommation et l’historique. Cette séparation claire entre acquisition, affichage, stockage et consultation améliore la maintenabilité, la sécurité et l’évolutivité du système, tout en respectant l’esprit low-tech du projet.
VI – VIDÉO DE DÉMONSTRATION
VII – PERSPECTIVES
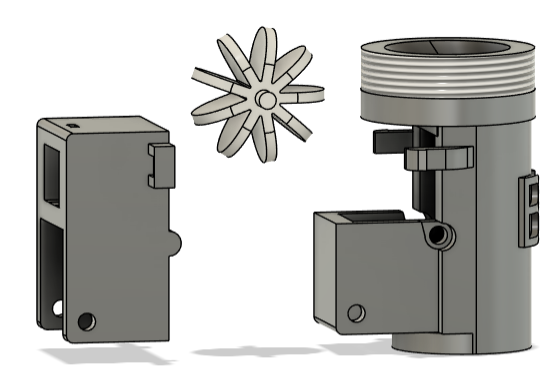
1 – Débitmètre
Pour garantir la fiabilité immédiate de notre solution, nous avons intégré un capteur standardisé. Toutefois, une piste d’évolution majeure réside dans l’auto-fabrication de ce composant clé. Nous avons d’ailleurs initié cette démarche avec un premier prototype imprimé en 3D. Bien que les défis d’étanchéité aient nécessité de reporter cette intégration, la conception constitue la prochaine étape logique pour maximiser l’autonomie et la réparabilité de notre système.

2 – Interface matérielle du serveur local
Concernant le serveur local, notre roadmap technique inclut l’intégration d’une interface de contrôle physique (LEDs d’état et boutons poussoirs). L’analyse de conception a révélé que l’implémentation optimale nécessite l’insertion d’un circuit de gestion directement sur les lignes d’alimentation de la Raspberry Pi. Cette modification matérielle, trop invasive pour le matériel de prêt utilisé durant le prototypage, permettrait d’offrir un pilotage matériel de la mise sous tension et de l’extinction.
Au-dessus du boîtier, un espace avait été prévu pour l’intégration de l’interface matérielle, destinée à accueillir les voyants lumineux et les boutons de commande.

3 – Autonomie de l’afficheur
Bien que le prototype actuel dispose d’un passage de câble pour une alimentation USB-A, l’objectif final est d’offrir une liberté totale de placement grâce à une alimentation autonome. Cette transition technologique ne présente aucun risque technique majeur : nous avons déjà implémenté avec succès cette solution d’autonomie sur le module Capteur. L’intégration d’une batterie sur l’Afficheur est donc la prochaine étape logique pour supprimer les contraintes de câblage dans la salle de bain ou la cuisine.
4 – Diminution de l’encombrement du système
Actuellement, notre architecture repose sur un capteur par point d’eau, ce qui multiplie les dispositifs. Une voie d’optimisation majeure consiste à passer à un unique capteur par pièce humide (ex: arrivée d’eau générale de la salle de bain). Grâce à des algorithmes d’analyse de flux, il est possible de différencier les signatures hydrauliques (le débit d’une douche est différent de celui d’un lavabo) pour réattribuer logiciellement la consommation à chaque équipement. Cela diviserait grandement le nombre de capteurs nécessaires.
VIII – ANNEXES
1 – Déploiement du serveur local
A. Prérequis
- Installer Raspberry Pi OS :
Pour ce faire, vous devez télécharger puis installer Raspberry Pi Imager sur votre ordinateur, de préférence dans sa version la plus récente.
Raspberry Pi Imager est un outil officiel développé par la Raspberry Pi Foundation permettant de préparer une carte SD en y installant facilement un système d’exploitation compatible avec les cartes Raspberry Pi.
Vous devez ensuite vous procurer une carte SD, puis la connecter à votre ordinateur à l’aide d’un lecteur de cartes. Il vous suffit alors de sélectionner la carte SD dans l’option « Stockage » et de lancer l’écriture.
Assurez-vous que « Raspberry Pi OS (Full) » est sélectionné dans l’option « Système d’exploitation », afin de disposer d’un environnement complet incluant l’interface graphique et les outils nécessaires au développement et à l’administration du serveur.
Enfin, insérez la carte SD dans le support prévu à cet effet sur la Raspberry Pi (RPI) et allumez là.

- Connecter la RPI à un réseau Wi-Fi local via l’interface graphique. En haut à droite de l’écran, cliquez sur l’icône de réseau pour ajouter un nouveau réseau Wi-Fi.
- Activer l’option SSH dans les paramètres « Interfaces » de la RPI.
Vous les trouverez en cliquant sur le logo de la RPI en haut à gauche, indiquant le centre de contrôle, puis en cherchant « interfaces ».
- Connectez votre ordi à la RPI en SSH.
Pour vous connecter en SSH, votre ordinateur doit être connecté au même réseau Wi-Fi que la RPI. Dans le terminal de votre ordinateur (qui doit disposer d’un client SSH), saisissez :
ssh <nom_d’utilisateur_de_la_RPI>@<adresse_IP_de_la_RPI>
Une ligne de saisie apparaît quand vous appuyez sur “Entrer” et vous demande le mot de passe de votre RPI. Vous pouvez maintenant utiliser le terminal de votre RPI depuis votre ordinateur.
B. Mettre à jour les dépôts et les paquets
Dans le terminal de la RPI, saisissez :
- sudo apt update
- sudo apt upgrade
C. Installer Apache
Apache (Apache HTTP Server) est un serveur web open source largement utilisé, dont le rôle est de recevoir les requêtes HTTP des clients (navigateurs web) et de leur fournir les pages web correspondantes. Il constitue l’un des composants fondamentaux d’une architecture web de type client–serveur.
- Dans un terminal, saisir : sudo apt install apache2
- Pour vérifier que tout fonctionne, trouvez l’adresse IP de la RPI, puis tapez dans votre navigateur : http://<adresse_IP_de_la_RPI>
Pour trouver l’adresse IP en ligne de commande, ouvrez un terminal et tapez : ip a. L’adresse IP apparaît après “inet” pour l’interface utilisée (eth0 pour Ethernet, wlan0 pour le Wi-Fi).

En cas de difficulté, vous pouvez consulter : https://raspberrytips.fr/comment-trouver-ip-raspberry-pi/
Vous devriez voir apparaître dans votre navigateur la page suivante :
D. Installer PHP
PHP est un langage utilisé pour le développement backend des sites Web.
Dans un terminal de la RPI, saisissez :
sudo apt install php libapache2-mod-php
E. Installer MySQL (MariaDB)
MariaDB est un système de gestion de base de données compatible avec MySQL.
- Installer MariaDB et le module PHP associé :
sudo apt install mariadb-server php-mysql
- Redémarrer Apache pour appliquer les changements :
sudo service apache2 restart
- Vous devez maintenant créer un utilisateur MySQL pour gérer vos bases de données.
MySQL nécessite une authentification pour garantir que seules les personnes autorisées peuvent accéder aux données.
Nous devez créer un super-utilisateur que vous utiliserez dans votre code PHP :
- Se connecter à MySQL :
sudo mysql - Créer une première base de données :
CREATE DATABASE test; - Créer votre premier utilisateur :
CREATE USER ‘<nom_utilisateur>’@’localhost’ IDENTIFIED BY ‘<mot_de_passe>’; - Lui donner les permissions sur la base :
GRANT ALL PRIVILEGES ON test.* TO ‘<nom_utilisateur>’@’localhost’; - Appliquer les changements :
FLUSH PRIVILEGES; - Quitter MySQL :
quit
F. Installer PhpMyAdmin
PhpMyAdmin permet de gérer la base de données depuis votre navigateur.
Pour l’installer, saisissez : sudo apt install phpmyadmin
Pendant l’installation :
- Sélectionnez Apache2 (espace puis entrée).
- Pour « Configurer la base de données pour phpmyadmin avec dbconfig-common », choisissez Non.
Après l’installation, rendez-vous sur : http://<adresse_IP_de_la_RPI>/phpMyAdmin
Vous devez voir apparaître la page ci-dessous, saisissez les informations de sécurité que vous avez attribué à votre super utilisateur MariaDB :
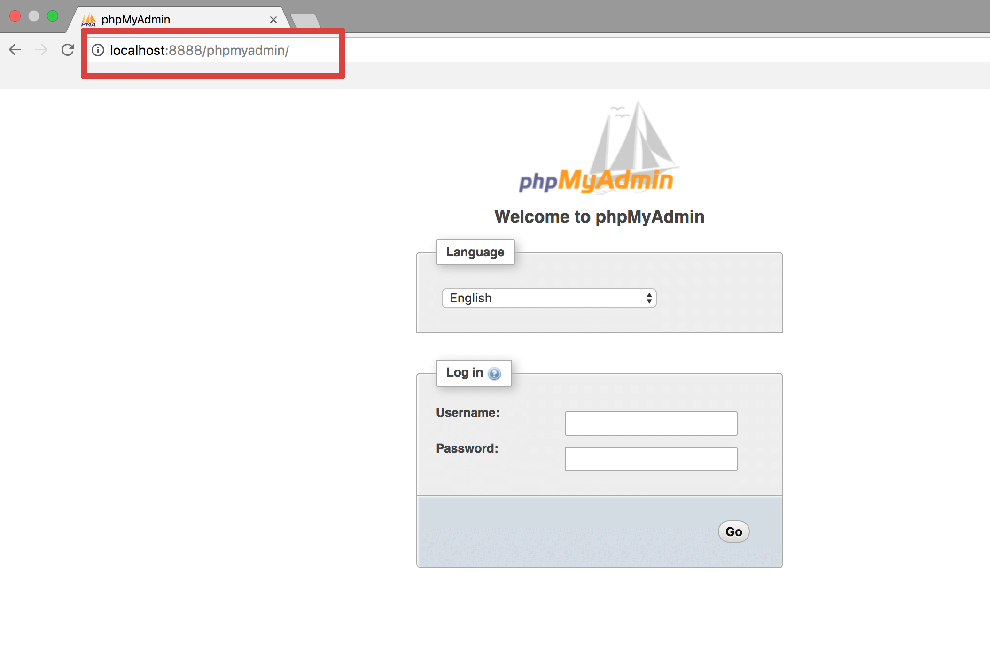
À présent, vous pouvez vous concentrer sur le développement de l’application web à l’aide de votre éditeur de texte ou environnement de développement préféré, puis téléverser le code sur la RPI, en veillant à configurer correctement les accès à la base de données ainsi que les droits d’accès d’Apache2 à l’ensemble des fichiers nécessaires.
Les fichiers du serveur web doivent être placés dans le répertoire : /var/www/html sur la RPI.
Dans notre implémentation, nous avons choisi de structurer l’application en deux répertoires distincts :
- Frontend, contenant l’interface utilisateur (HTML, CSS, JavaScript, etc.) ;
- Backend, regroupant la logique serveur et les scripts d’accès à la base de données tous contenus dans des fichiers PHP.
Ces deux répertoires sont eux-mêmes situés dans le répertoire dédié mentionné ci-dessus, afin d’être accessibles par le serveur web Apache.
Cailloux – Blog Solution Technique
Blog Solution Technique
1. Contexte
Dans le cadre du Projet Conception D’objets Utiles, Accessibles et Durables du cursus Ingénieur de l’IMT Atlantique, notre équipe a choisi d’aborder une problématique environnementale et sociétale majeure : le recul du trait de côte du littoral français.
Comme nous l’avions précédemment étudié dans notre état de l’art, ce patrimoine naturel et économique est en situation critique. L’érosion est largement amplifiée par la pression humaine (urbanisation, tourisme) qui s’ajoute aux phénomènes naturels (tempêtes, montée des eaux). Actuellement, près de 1 720 km de côtes sont affectés, avec des pertes pouvant atteindre un demi-mètre par an, menaçant directement les écosystèmes, les infrastructures et l’économie locale.
Forts de ce constat, et observant le besoin d’une réponse plus structurée et coordonnée entre les différents acteurs locaux, nous avons décidé de concevoir et de réaliser une solution technique innovante. Notre objectif est clair : développer un outil permettant d’optimiser l’efficacité de la réponse collective grâce à une meilleure information, coordination et sensibilisation des parties prenantes.
Notre solution est une application ludique permettant de comprendre les enjeux du recul du trait de côte.
Nous vous présentons ici la conception, la réalisation et les choix architecturaux (matériels et logiciels) de cette solution, ainsi qu’une démonstration de son fonctionnement.
2. Réalisation
A. Description de notre solution
Notre application a été conçue pour maximiser l’impact de la sensibilisation en l’abordant sous un triple angle : elle propose des défis de culture générale, éclaire l’utilisateur sur les conséquences de ses décisions, et visualise les effets du changement climatique via des cartes interactives de l’élévation du niveau marin.
Défis de Culture Générale : Le rendez-vous quotidien de l’information
Cette section est pensée pour ancrer l’apprentissage dans une routine ludique. Les questions de culture générale, entièrement centrées sur la problématique du recul du trait de côte, l’érosion marine et les solutions d’adaptation, sont mises à jour quotidiennement. Ce renouvellement constant garantit que l’utilisateur trouve toujours un intérêt à ouvrir l’application, transformant la sensibilisation en un rituel régulier. C’est un moyen simple et efficace de consolider les connaissances et de mesurer sa progression dans la compréhension des enjeux locaux.
Conséquence des Décisions : Plongez au cœur de l’action collective
Il s’agit du cœur interactif de l’application. Ce module prend la forme d’un jeu de simulation où l’utilisateur incarne le maire d’une ville côtière. Face à des scénarios réalistes (montée des eaux, projets immobiliers, manifestations, budgets limités), l’utilisateur doit prendre des décisions. L’objectif est triple : répondre aux besoins immédiats des habitants, respecter les cadres législatifs de l’État, et préserver la planète. Ce jeu permet de faire l’expérience directe de la complexité de la gestion côtière et d’évaluer l’impact à long terme de chaque choix sur la résilience du territoire.
Carte d’Élévation : Visualiser l’urgence du changement climatique
La carte interactive offre la dimension la plus concrète et percutante de l’application. En utilisant des données géographiques et des projections d’élévation du niveau marin, cette fonctionnalité permet aux utilisateurs de visualiser directement les zones inondables et les territoires potentiellement menacés. Cet outil cartographique est essentiel pour transformer des statistiques abstraites en une réalité tangible, renforçant la sensibilisation et l’urgence d’agir, notamment en ciblant les populations vivant ou travaillant dans ces zones à risque.
B. Outils
Pour réaliser notre projet nous avons utilisé :
- VS Code
- Android Studio
- Expo GO
- Google Maps API
- Expo SDK
- Bibliothèque React Native
C. Réalisations
La conception de notre application a nécessité une approche structurée. Nous détaillons ci-dessous la réalisation de chacune des trois parties de notre application. Ces trois parties sont accessibles via trois boutons disponibles sur l’activité d’accueil de l’application. Les chemins d’utilisation sont les suivants :
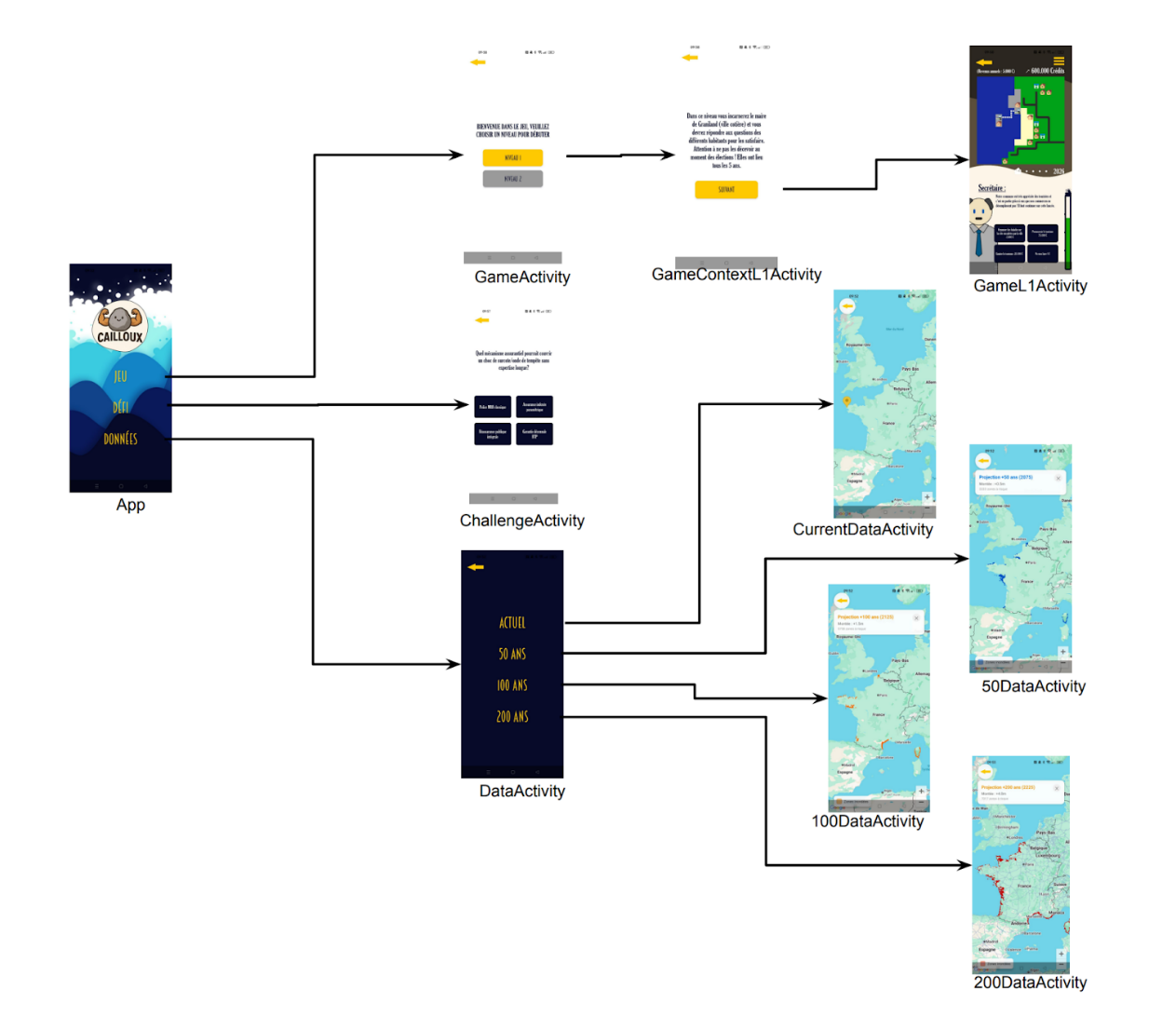
Figure 1: Schéma chemins d’utilisation application Cailloux
Pour expliquer plus facilement le principe et le fonctionnement de notre solution, nous avons choisi d’utiliser des diagrammes de classe dans les sections qui suivent. Ces schémas nous permettent de visualiser clairement la logique et la structure de chaque composante du projet. Afin de visualiser la structure complète de l’application, nous présentons un diagramme de classe global.
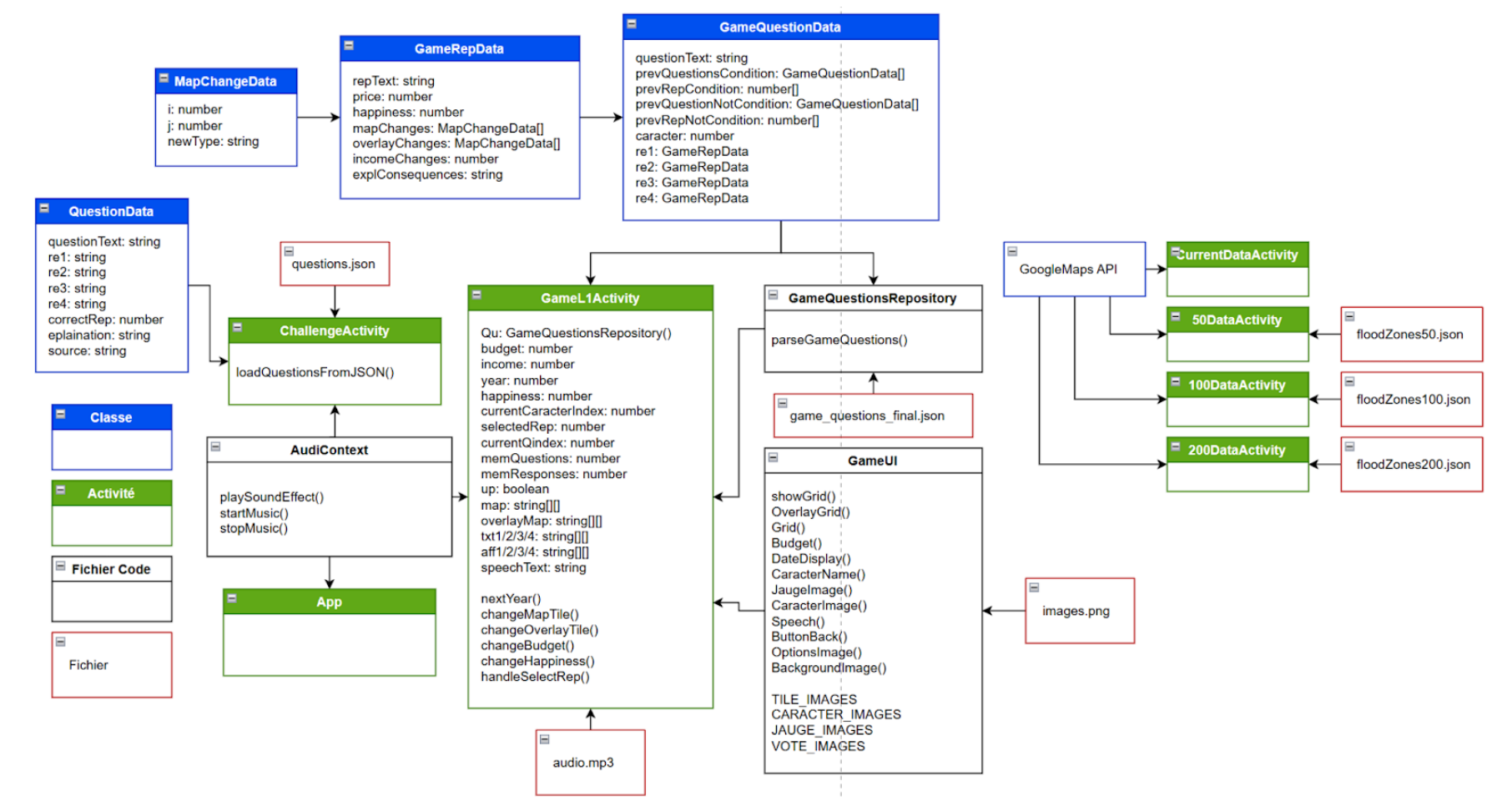
Figure 2: Diagramme de classe application Cailloux
Sur ce diagramme de classe on repère quatre différents éléments définis tel que :
| Élément | Explication de la notion |
| Classe | Le plan de construction qui définit les informations (les données) et les actions possibles (les fonctions) d’un élément du système. |
| Activité | Un écran unique de l’application mobile (ChallengeActivity, GameL1Activity). C’est l’interface avec laquelle l’utilisateur interagit. |
| Fichier Code | Le fichier contient les instructions de programmation de l’application (le code source). |
| Fichier | Une ressource externe qui n’est pas du code : les fichiers de données JSON (pour les questions et scénarios), les images, les sons. |
Figure 3 : Tableau Notions Diagramme de Classe
Partie 1 : défis de culture générale
Lorsque l’utilisateur clique sur “DÉFI”, il s’ouvre une activité (ChallengeActivity) laissant apparaître la question du jour et ses quatre propositions de réponse.
Diagramme de classe :
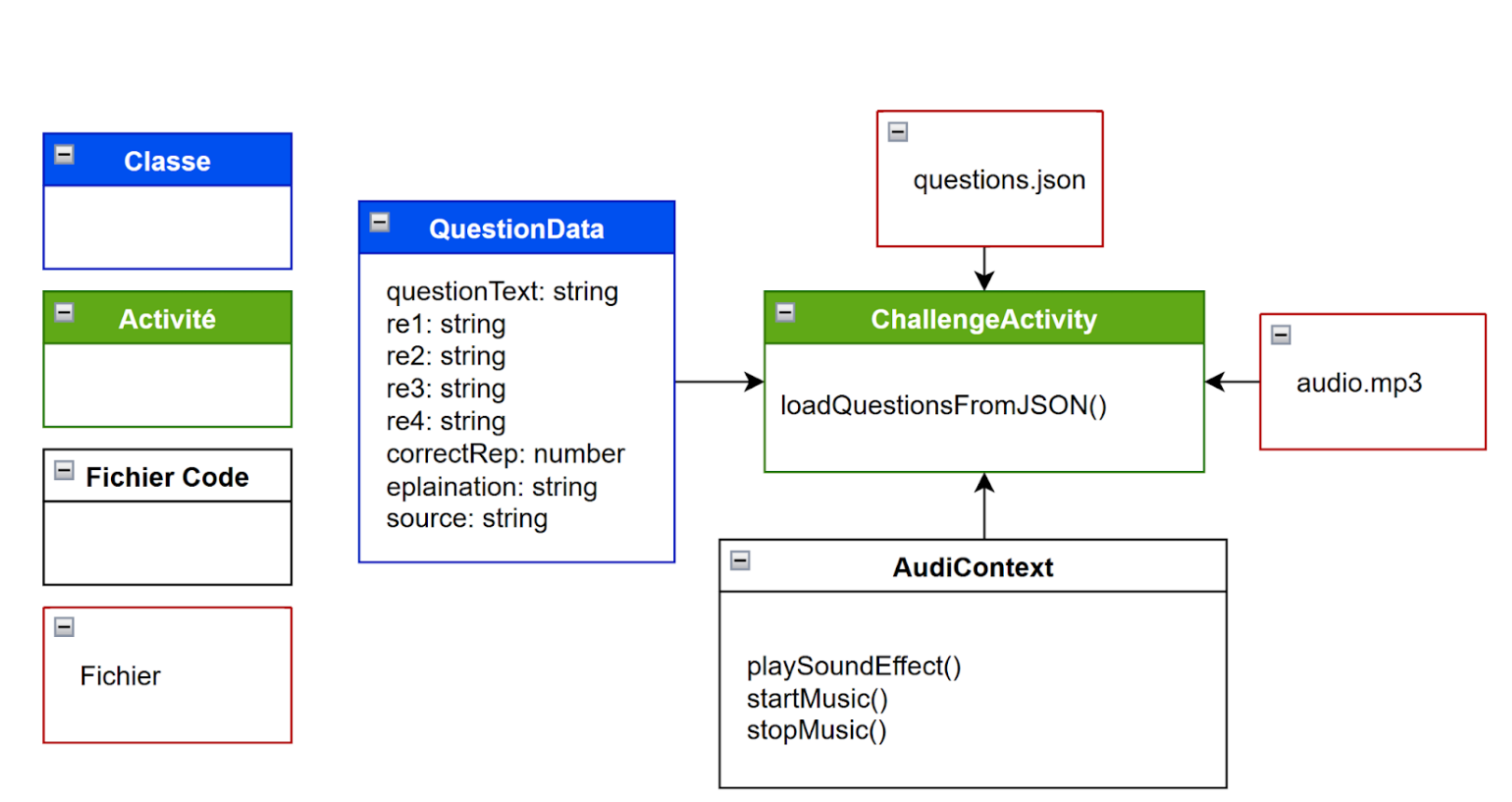
Figure 4: Diagramme de classe défis Cailloux
Dans une démarche lowtech, nous souhaitions trouver une manière de stocker les données sans avoir à utiliser un outil de stockage à distance. Ainsi, les 365 questions des défis quotidiens ont été stockées dans un fichier json directement dans le code de l’application. Ce fichier se présente sous cette forme :
{
« question1 »: {
« index »: 1,
« text »: « Quelles sont les principales forces naturelles responsables de l’érosion côtière ? »,
« rep1 »: « L’action des vagues »,
« rep2 »: « La dissolution chimique des roches calcaires »,
« rep3 »: « Les tempêtes et ouragans »,
« rep4 »: « La sédimentation fluviale »,
« correctRep »: 1,
« explan »: « Les vagues exercent une action mécanique continue sur la côte, favorisant le détachement et le transport de matériaux. »,
« source »: « BRGM, 2024 — “Littoral, risques côtiers et changement climatique.” »
},
« question2 »: {…
Face aux contraintes de temps, nous avons fait appel à l’Intelligence Artificielle pour la création de la majorité des questions. Bien que cela puisse impliquer une relecture ou un ajustement ponctuel, le format JSON choisi pour stocker cette banque de 365 défis permet à de futurs administrateurs, même non développeurs, de renouveler ou d’adapter ce contenu très facilement
C’est ce contenu, désormais structuré et facilement administrable au format JSON, qui est mis en œuvre : les informations sont directement récupérées, grâce à la fonction loadQuestionsFromJson, par l’activité ChallengeActivity.
L’activité charge et affiche le défi en s’appuyant sur la classe QuestionData, qui modélise le format des questions issues du fichier externe. Elle utilise ensuite les objets natifs de React Native (boutons, images, textes, etc.) pour présenter la question quotidienne (déterminée par la date du téléphone) et gérer l’interaction. Par exemple, l’activité fait appel aux fonctions du module AudioContext et à des fichiers mp3 stockés dans les assets pour générer des effets sonores de victoire ou de défaite selon la réponse de l’utilisateur.
Partie 2 : jeu de simulation
Cliquer sur le bouton jeu lance une activité de choix de niveau (GameActivity) puis une activité de contexte du niveau 1 (GameContextL1Activity) et enfin l’activité du niveau lui-même (GameL1Activity).
Diagramme de classe :
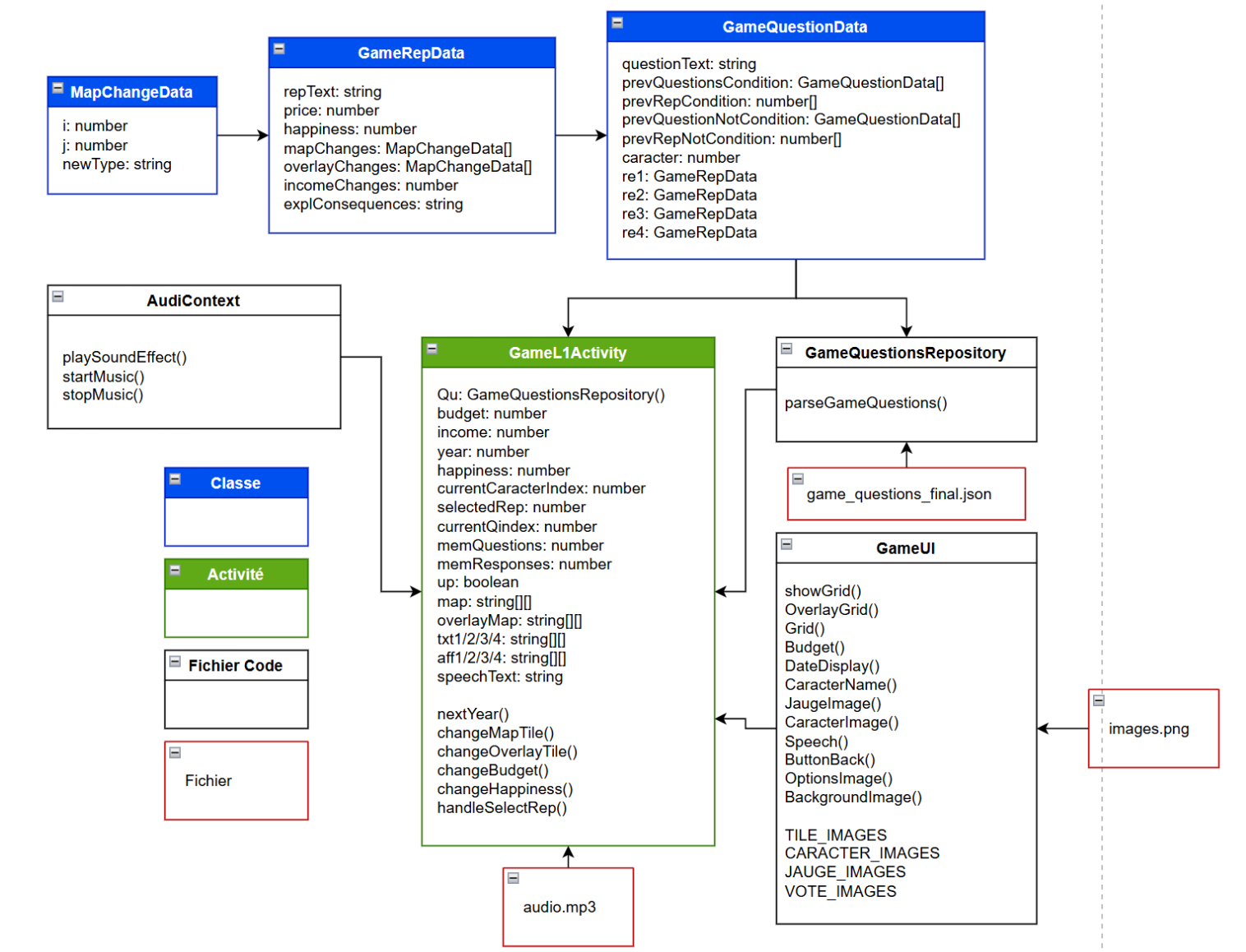
Figure 5: Diagramme de classe Jeu Cailloux
La partie Jeu de l’application est la partie la plus complexe du projet. Le scénario est basé sur un fichier json de la forme :
[{
« questionText »: « Notre commune… »,
« prevQuestCondition »: [],
« prevRepCondition »: [],
« prevQuestNotCondition »: [],
« prevRepNotCondition »: [],
« caracter »: 5,
« rep1 »: {
« repText »: « Organiser des balades… »,
« price »: -5000,
« happiness »: -10,
« mapChanges »: [],
« overlayChanges »: [],
« incomeChanges »: 0,
« explConseq »: « Ce choix permet d’attirer … »
},
« rep2 »: {
« repText »: « Promouvoir le tourisme »,
« price »: 75000,
« happiness »: 5,
« mapChanges »: [],
« overlayChanges »: [],
« incomeChanges »: 1000,
« explConseq »: « Graniland est plus attractive … »
},
« rep3 »: {
« repText »: « Limiter le tourisme »,
« price »: -20000,
« happiness »: -10,
« mapChanges »: [],
« overlayChanges »: [],
« incomeChanges »: -1000,
« explConseq »: « Ce choix a un impact négatif … »
},
« rep4 »: {
« repText »: « Ne rien faire »,
« price »: 0,
« happiness »: 0,
« mapChanges »: [],
« overlayChanges »: [],
« incomeChanges »: 0,
« explConseq »: « Cette décision n’a aucun impact … »
}
},{…
Nous avons instauré une logique conditionnelle dans le scénario. Les paramètres prevQuestCondition et prevRepCondition déterminent les questions qui doivent avoir été posées et les réponses spécifiques qui doivent avoir été sélectionnées pour que la question actuelle apparaisse. Les versions Not de ces paramètres gèrent les situations où une question ou une réponse passée doit ne pas avoir eu lieu pour déclencher la question en cours.
De même, nous avons instauré des paramètres de changement de la carte mapChanges et overlayChanges qui sont de la forme :
[ {« i »: 2,« j »: 6,« newType »: « h »},
{« i »: 3,« j »: 6,« newType »: « h »}]
Ces changements de carte sont enregistrés dans le code grâce à la classe MapChangeData. GameQuestionData, utilisant GameRepData et MapChangeData, permet de récupérer les informations du json. L’intérêt du json est le même que dans la partie Défi, un administrateur non développeur peut facilement modifier ou créer des scénarios.
La fonction parsGameQuestions de GameQuestionRepository est chargée de la lecture du json et de la création de la liste de questions.
Une question particulière nommée explication permet l’affichage des explications des conséquences aux réponses choisies. Elle est repérée par le code car c’est la seule à utiliser le personnage numéro 0 (la présentatrice). La liste de questions alterne une question réelle et une explication. La liste de questions est ensuite appelée dans GameL1Activity qui affiche l’interface du jeu.
export const Explication = new Q.GameQuestionData(« »,[],[],[],[],0,
new Q.GameRepData(« », 0, 0, [], [], 0, « »),
new Q.GameRepData(« », 0, 0, [], [], 0, « »),
new Q.GameRepData(« », 0, 0, [], [], 0, « »),
new Q.GameRepData(« », 0, 0, [], [], 0, « »))
Les fonctions d’affichage du jeu sont communes à tous les niveaux existants (un seul pour l’instant) et sont répertoriées dans le fichier tsx GameUI. Ce dernier importe directement les ressources graphiques (images des personnages, jauges, tuiles de carte, etc.) depuis les assets. En revanche, les fichiers audios sont appelés directement depuis GameL1Activity. Ce choix a été fait car ils sont exclusivement déclenchés par la modification des variables d’état de l’activité (comme le budget ou la carte) et non par l’interface d’affichage elle-même. Leur lecture est assurée par des fonctions provenant du tsx AudioContext, le même module que celui utilisé pour la partie “Défis”.
La fonction HandleSelectRep est la plus importante de l’activité de jeu, elle apparaît à chaque fois que l’utilisateur clique sur une réponse. La fonction assure le déroulement du scénario en distinguant deux types de questions. Si la question est à un indice pair dans la liste de questions, il s’agit d’une véritable question. Les quatre boutons de choix sont alors affichés en plus du texte de question. Au contraire, si l’indice est impair c’est que la question est en réalité une explication à la question précédente. Dans ce cas seul le premier bouton de réponse est affiché avec le texte “Suivant”. La question de type explication n’a jamais d’effet sur le jeu, c’est seulement un texte. L’utilisateur clique simplement sur suivant quand il a fini de lire pour passer à la question suivante qui nécessitera une réponse.
Certaines vraies questions peuvent également être de type ‘événement’ renseigné par le fait qu’elles sont présentées par le personnage 0 alors qu’elles ont un indice pair dans la liste. HandleSelectRep est alors conçu pour n’afficher qu’un seul bouton, la seule issue laissée par l’événement. A l’inverse d’une explication, cette issue a réellement des conséquences sur l’état du jeu. Dans le cas d’une “question évenement”, on considère que l’explication est déjà dans le texte de la question. HandleSelectRep est donc conçu pour sauter l’explication suivante.
Une dernière fonctionnalité de HandleSelectRep est d’assurer la cohérence du scénario. Elle utilise la fonction “respects” (définie dans GameUI) pour vérifier si les conditions de prérequis d’une question sont remplies. Ces conditions incluent la vérification des questions/réponses qui doivent avoir eu lieu (prevQuestCondition et prevRepCondition), ainsi que celles qui ne doivent pas s’être produites (prevQuestNotCondition et prevRepNotCondition). Si la fonction respects renvoie une non-validation, la question et son explication sont automatiquement sautées.
L’activité de jeu (GameL1Activity) se termine immédiatement dès qu’une condition de défaite est atteinte : soit le budget tombe à zéro (n’importe quelle année), soit la satisfaction citoyenne passe sous les 50% (lors d’une année électorale). La fermeture de l’activité déclenche alors un retour vers l’écran de contexte (GameContextL1Activity), auquel est transmis un ordre de modification. Cet ordre adapte l’affichage (changement du fond, lancement de la musique de défaite et texte explicatif) en fonction de la raison de la défaite (Banqueroute ou non-réélection).
Dans le cas où l’on atteint la fin du scénario sans aucune défaite, l’activité GameL1Activité est fermée. Elle transmet alors à GameContextL1Activityun ordre de modification correspondant à la victoire (musique de victoire, fond vert, etc.).
Partie 3 : cartes interactives
Lorsque l’utilisateur clique sur « Donnée », une activité DataActivity s’ouvre, lui permettant de sélectionner l’année de projection souhaitée dans le futur (0, 50, 100 ou 200 ans). A chaque choix correspond une nouvelle activité (CurrentDataActivity, 50DataActivity…).
Diagramme de classe :
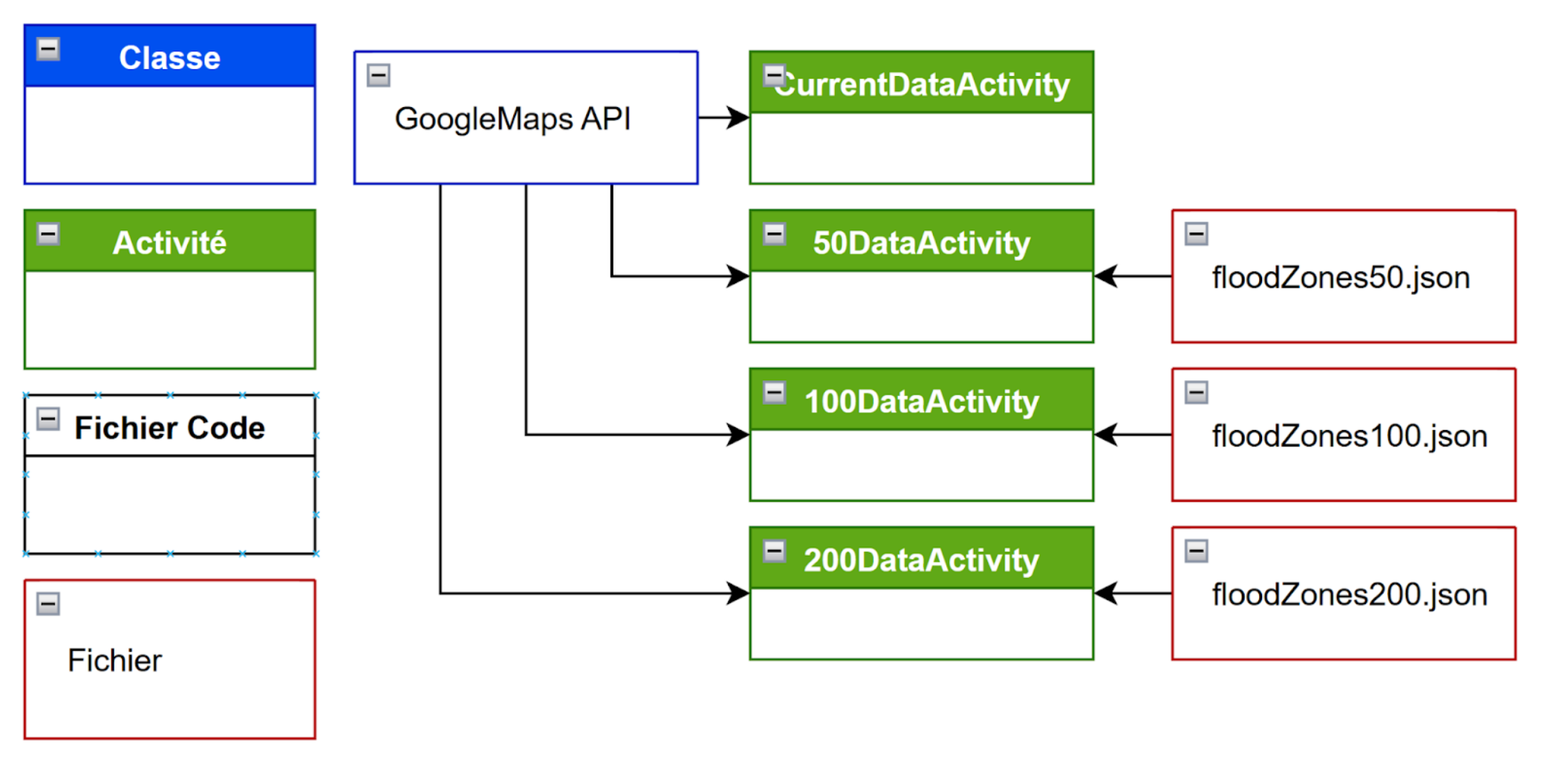
Figure 6: Diagramme de classe Carte Cailloux
Les quatre activités sont configurées de la même manière. Elles utilisent l’API Google Maps de sorte à afficher une carte du monde sur laquelle on peut se déplacer. On en reste là pour CurrentDataActivity car il s’agit juste de l’état de la carte actuelle. Dans les trois autres cas, l’activité importe les informations d’un fichier json correspondant. Ils sont de la forme :
{
« id »: « zone_50y_1 »,
« coordinates »: [
{
« latitude »: 42.54177440109096,
« longitude »: 3.051441054077814
},{
« latitude »: 42.541792380354515,
« longitude »: 3.051441069917069
},{
« latitude »: 42.54177441280101,
« longitude »: 3.051416740695078
},{
« latitude »: 42.54177440109096,
« longitude »: 3.051441054077814
}]},
Chaque zone correspond à une surface de terrain submergée par les eaux de la mer. L’API permettant de créer des surfaces vectorielles de surlignage par dessus la carte, on peut afficher ces zones inondées.
Concernant cette partie de l’application, nous avons dû nous adapter car la quantité de données comparables dans un fichier APK était limitée. Dans le but de fluidifier la navigation sur les cartes, nous avons choisi de réduire la quantité de points récupérés sur le site de la Nasa en limitant l’affichage des zones inondées à la France métropolitaine et en réduisant la résolution de leurs bords.
3. Résultats
Notre projet s’est concrétisé par le développement d’une application mobile éducative et ludique pour la sensibilisation au recul du trait de côte. Le prototype est une plateforme fonctionnelle, construite à l’aide de React Native/Expo et intégrant l’API Google Maps pour la visualisation des zones inondables.
L’architecture logicielle repose sur des fichiers JSON qui contiennent à la fois la banque des 365 défis de culture générale et la logique complexe du jeu de simulation. Ce choix permet de dissocier le contenu du code, facilitant la mise à jour et l’évolution des scénarios par un administrateur non-développeur.
Un compromis technique majeur concerne la partie Cartes d’Élévation : pour garantir la fluidité de l’application et maîtriser la taille du fichier d’installation (APK), nous avons dû réduire la résolution des données géographiques et limiter l’affichage des zones inondées à la France métropolitaine.
Démonstration :
Figure 7: Vidéo Démonstration Cailloux
4. Perspectives
L’expérience utilisateur et l’impact de notre application peuvent encore être considérablement renforcés. Nous avons, ci-dessus, identifié et exploré plusieurs pistes d’amélioration.
Tout d’abord, une évolution significative consisterait à transformer le jeu de simulation en un d’atelier collaboratif. L’idée serait de permettre à plusieurs utilisateurs d’incarner simultanément différentes parties prenantes (élu, citoyen, scientifique…) afin de prendre des décisions complexes de manière collective. Le mode collaboratif ancrerait la simulation dans la réalité de la gouvernance locale, ce qui en ferait un support utile pour les réunions de sensibilisation avec les vrais acteurs du territoire.
Parallèlement, la logique du jeu de simulation doit être affinée pour mieux représenter les dilemmes de l’action publique. Actuellement limitée à la victoire ou à la défaite (selon le budget et la satisfaction), nous souhaiterions introduire une troisième issue : le succès environnemental à long terme malgré un échec électoral à court terme. Cette nuance se déclencherait si le maire favorise la protection de l’environnement par des mesures impopulaires, subissant une défaite électorale mais sauvant le littoral. Cela permettrait de sensibiliser à la tension entre l’urgence politique et la nécessité écologique.
Ensuite, nous pensons pertinent de créer de nouveaux niveaux pour le jeu de simulation, se déroulant dans des lieux géographiques distincts afin de montrer que le recul du trait de côte affecte une diversité de milieux (littoral rocheux, estuaire, zones de marais) et non uniquement le front de mer touristique.
De plus, les défis quotidiens pourraient évoluer pour inclure de la science participative. L’application inviterait les utilisateurs à des actions concrètes sur le terrain (relevés, photos, observations) qui enrichiraient des bases de données réelles, transformant la routine ludique en un engagement civique et scientifique direct.
Enfin, nous devrons compléter les données des cartes d’élévation pour, si la performance de l’application le permet, intégrer des résolutions plus fines et étendre la couverture géographique au-delà de la France métropolitaine, offrant ainsi une visualisation encore plus complète des infrastructures menacées.
L’ensemble de ces pistes d’amélioration représente notre feuille de route pour faire évoluer l’application vers un outil encore plus complet, à la fois plus puissant, plus réaliste et plus engageant pour l’avenir de la protection du littoral.
Maker Lens – Centraliser les Tutoriels Low-Tech
Projet MakerLens : Centraliser les Tutoriels Low-Tech
Envoyé par l’équipe MakerLens le 15 Décembre 2024
Équipe :
Bérénice CARDOSO-FAUCHER, Pol TYMEN, Alex PEIRANO, Marc DUBOC, Divine BANON, Lucas OLIVER
I – Contexte
Durant le cursus Ingénieur généraliste de l’IMT Atlantique, les élèves doivent réaliser un projet fil rouge TAF COUAD. C’est dans ce cadre que nous avons développé MakerLens, une application web pour centraliser et rendre accessible la documentation low-tech.
L’idée derrière ce projet est de répondre à un problème concret identifié lors de notre enquête terrain : la fragmentation de la documentation. En effet, les tutoriels low-tech existent mais sont éparpillés sur de multiples plateformes (YouTube, Wikis, Blogs), souvent mal structurés et difficiles à filtrer.
Résultat : les débutants abandonnent et les médiateurs (fab managers, enseignants) perdent un temps considérable à chercher des ressources adaptées.
Ainsi, nous avons réalisé une plateforme web qui grâce à un moteur de recherche intelligent et des filtres pratiques (coût, difficulté, durée) permet de trouver rapidement le bon tutoriel. L’application ne crée pas de nouveau contenu mais agrège et standardise l’existant pour le rendre accessible à tous.
Lien vers l’application : https://promaaa.github.io/maker_lens/
Vidéo de présentation
Présentation complète du projet MakerLens (5 minutes)
II – Réalisation
1) Matériel nécessaire
L’avantage de MakerLens : c’est une solution 100% logicielle qui ne nécessite aucun matériel spécifique !
Côté utilisateur :
- N’importe quel appareil avec un navigateur web (ordinateur, tablette, smartphone)
- Une connexion Internet (ou version téléchargeable pour utilisation hors-ligne)
Côté développement :
- Un ordinateur pour coder
- Un compte GitHub (gratuit)
- Python 3 installé (pour les scripts de récupération de données)
Justification low-tech : En étant 100% logiciel, MakerLens maximise l’utilisation des équipements existants et évite la création de nouveaux déchets électroniques.
2) Architecture globale
L’application repose sur une architecture simple en 3 couches :
Couche 1 – Collecte des données (Scripts Python)
- Des scripts Python scrapent les sites sources (Low-Tech Lab, Instructables, etc.)
- Les données sont extraites et converties dans un format standardisé JSON
- Validation manuelle pour garantir la qualité
Couche 2 – Hébergement (GitHub Pages)
- Le site est hébergé gratuitement sur GitHub Pages
- Architecture « fichiers statiques » = pas de serveur complexe à gérer
- Consommation énergétique minimale
Couche 3 – Interface utilisateur (HTML + JavaScript)
- Interface web légère en HTML/CSS/JavaScript pur (pas de frameworks lourds)
- Moteur de recherche côté client avec Fuse.js (~26 Ko seulement)
- Filtres dynamiques sans rechargement de page


Interface principale de MakerLens
3) Fonctionnalités principales
a) Mode Création vs Mode Recyclage
- Mode Création : Pour fabriquer un objet à partir de zéro
- Mode Recyclage : Pour transformer et réutiliser des objets existants
Cette séparation encourage l’économie circulaire en valorisant le réemploi.

Mode Création : Fabriquer des objets à partir de zéro

Mode Recyclage : Transformer et réutiliser des objets existants
b) Recherche intelligente
Le moteur de recherche tolère les fautes de frappe : tapez « arduin » et vous trouverez quand même tous les tutoriels Arduino ! La recherche se fait instantanément côté client, sans appeler de serveur.
Exemple d’utilisation : Un étudiant cherche « panneau solaire » → L’application trouve tous les tutoriels contenant ces mots dans le titre, la description ou les mots-clés.
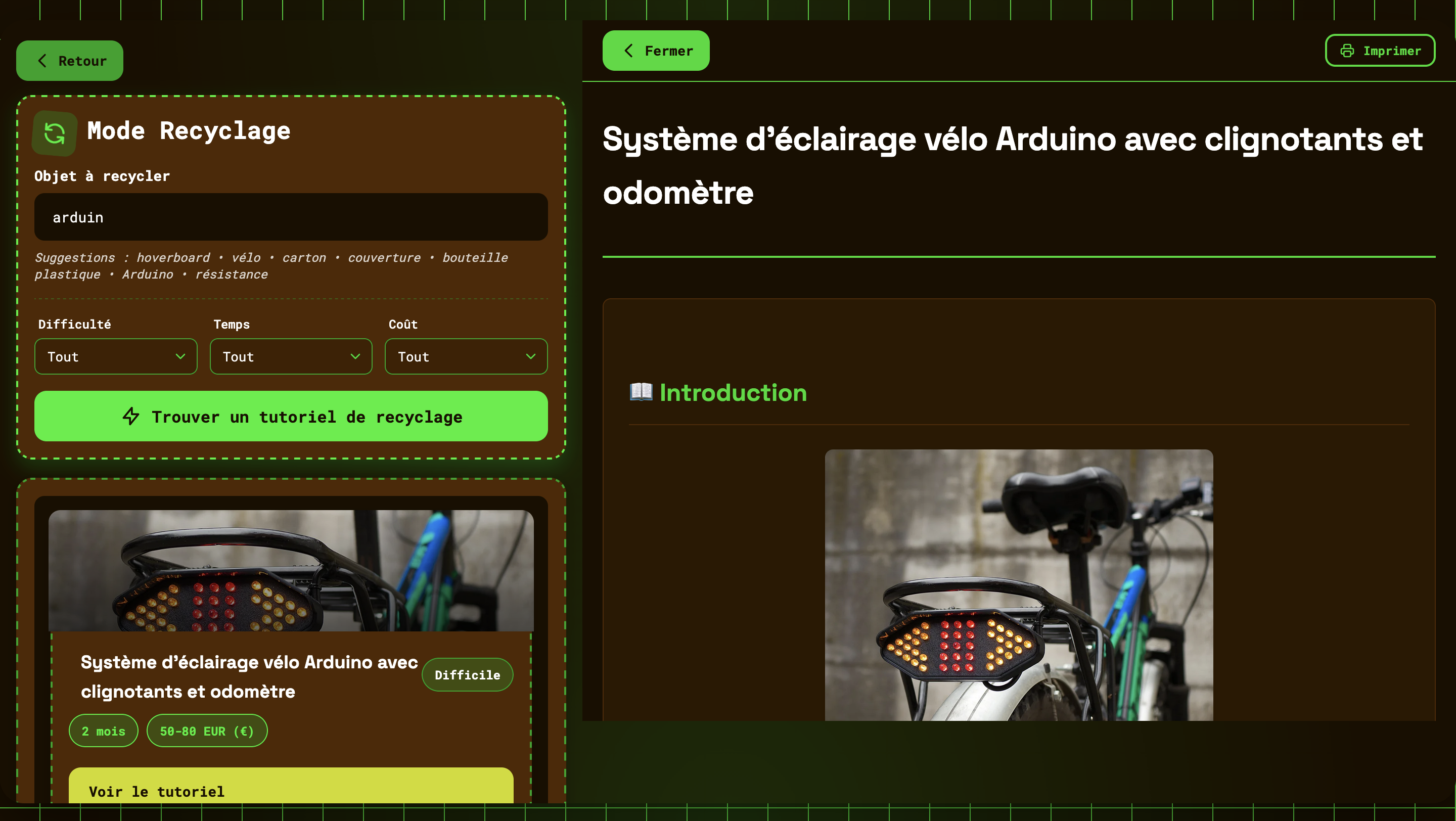

Exemple de recherche avec faute d’orthographe : « arduin » trouve quand même les tutoriels Arduino
c) Filtres pratiques
Trois filtres pour affiner la recherche :
| Filtre | Options | Utilité |
|---|---|---|
| Coût | € (moins de 10€) €€ (10-50€) €€€ (plus de 50€) |
Adapter à son budget |
| Difficulté | Facile Moyen Difficile |
Choisir selon son niveau |
| Durée | Temps en heures | Planifier son projet |
Exemple d’utilisation : Un débutant sélectionne « Facile » + « € » → Il obtient uniquement des projets simples et peu coûteux.

d) Format standardisé des tutoriels
Tous les tutoriels suivent la même structure :
- En-tête : Titre, difficulté, coût, durée, source
- Introduction : Description du projet
- Matériel requis : Liste complète
- Instructions étape par étape : Numérotées et illustrées
- Notes et conseils : Astuces pratiques
Fini les tutoriels incomplets ou mal organisés !
4) Technologies utilisées
Nous avons privilégié des technologies simples et pérennes :
| Technologie | Utilisation | Pourquoi ce choix ? |
|---|---|---|
| HTML5 + CSS3 | Structure et design | Standards web, légers et durables |
| JavaScript Vanilla | Logique de l’application | Pas de framework lourd type React |
| Fuse.js | Recherche floue | Bibliothèque ultra-légère (26 Ko) |
| Python 3 | Scripts de scraping | Langage standard et bien documenté |
| BeautifulSoup | Extraction de données web | Simple et efficace |
| JSON | Format de données | Lisible, éditable, interopérable |
| GitHub Pages | Hébergement | Gratuit, pas de serveur à gérer |
5) Structure des données (format JSON)
Chaque tutoriel est stocké dans un fichier JSON qui contient :
{
"titre": "Marmite norvégienne",
"description": "Cuiseur économe en énergie",
"difficulte": "facile",
"cout": "€",
"duree_heures": 2,
"mode": "creation",
"mots_cles": ["cuisine", "isolation", "économie d'énergie"],
"materiel": ["Caisse en bois", "Isolant", "Couvercle"],
"etapes": [
{
"numero": 1,
"titre": "Préparation de la caisse",
"description": "Nettoyer la caisse..."
}
],
"source": {
"nom": "Low-Tech Lab",
"url": "https://wiki.lowtechlab.org/...",
"licence": "CC BY-SA"
}
}
Ce format permet :
- Une lecture facile par l’humain
- Une modification sans outil spécialisé
- Une exportation vers d’autres plateformes
- Un suivi des versions avec Git
6) Processus de développement (Méthode Scrum)
Nous avons organisé le projet en 3 sprints agiles :
Sprint 1 (Septembre 2024) – Enquête & Prototype
- Entretiens avec fab managers, enseignants et makers
- Validation des besoins utilisateurs
- Création de personas (Aude la fabmanageuse, Daniel le débutant, Ethan l’enseignant)
- Première version du format JSON
Sprint 2 (Octobre 2024) – Moteur de recherche & Scraping
- Développement du moteur de recherche avec Fuse.js
- Scripts de scraping pour extraire les tutoriels du Low-Tech Lab
- Implémentation des filtres (coût, difficulté, durée)
- Intégration de la base de données à l’interface
Sprint 3 (Novembre 2024) – Interface & Accessibilité
- Finalisation de l’interface responsive (mobile, tablette, desktop)
- Optimisation pour les daltoniens (contraste, couleurs)
- Nettoyage de la base de données (suppression des doublons)
- Déploiement sur GitHub Pages
7) Difficultés rencontrées
Problème 1 : Sources hétérogènes
Situation : Les tutoriels scrapés depuis différents sites ont des formats très variés (listes à puces, paragraphes, images manquantes…).
Solution : Nous avons créé un format JSON standardisé et écrit un convertisseur spécifique pour chaque source. Une validation manuelle garantit la qualité finale.
Problème 2 : Précision de la recherche
Situation : Un utilisateur cherche « vélo » et tombe sur un tutoriel de « biosphère autonome » qui utilise un pédalier…
Solution : Nous avons ajusté les poids dans Fuse.js pour privilégier le titre et les mots-clés principaux. La précision est passée de ~65% à ~85%.
Problème 3 : Accessibilité visuelle
Situation : Lors du Sprint Review, les évaluateurs ont signalé que nos couleurs (jaune/vert) manquaient de contraste pour certains daltoniens.
Solution : Tests avec simulateurs de daltonisme et ajustement des nuances pour respecter les normes WCAG 2.1. Ajout d’icônes en complément des couleurs.
III – Résultats
Notre projet de création d’une plateforme de centralisation des tutoriels low-tech s’est soldé par la mise en ligne d’une application web fonctionnelle accessible à tous.
Points forts du projet
- ~150 tutoriels harmonisés et accessibles
- Recherche instantanée : temps de réponse ~50 ms
- Poids léger : page d’accueil de seulement 350 Ko
- Open source : code disponible sur GitHub pour contributions futures
- Zéro déchet électronique : solution 100% logicielle
Limites et améliorations possibles
Comme tout prototype, MakerLens peut encore être amélioré :
- Dépendance Internet : L’application nécessite une connexion web. Solution envisagée :
développer une Progressive Web App (PWA) pour un fonctionnement hors-ligne complet. - Langue unique : Actuellement en français seulement. Solution : internationalisation de
l’interface pour toucher une audience mondiale. - Contribution communautaire : Pour l’instant, seule l’équipe dev peut ajouter des tutoriels.
Solution : créer un éditeur visuel permettant à tous de contribuer facilement.
Feuille de route pour la communauté (Roadmap)
Le code étant Open Source, nous invitons les étudiants, développeurs et makers à s’approprier MakerLens. Voici une liste de fonctionnalités concrètes que nous identifions pour la suite, prêtes à être développées par d’autres :
- Ajout d’autres sites scrapés : Étendre la base de données en développant de nouveaux scripts pour intégrer d’autres sources de tutoriels libres.
- Système de favoris local (LocalStorage) : Développer une fonction permettant aux utilisateurs de marquer des tutoriels comme « À faire ». Le défi est de stocker ces données directement dans le navigateur (via localStorage) pour éviter toute gestion de compte et respecter la vie privée.
- Filtre par « Outillage disponible » : Créer un « filtre inversé » innovant où l’utilisateur coche les outils qu’il possède (ex: scie sauteuse, fer à souder). L’algorithme ne proposerait alors que les projets réalisables immédiatement, réduisant la frustration des débutants.
- Comparateur de solutions : Implémenter une vue permettant d’afficher deux tutoriels côte à côte (ex: deux versions de « Marmite norvégienne ») pour comparer le matériel requis et la complexité.
- Intégration d’un bouton « Signaler une erreur » : Ajouter un lien simple sur chaque tutoriel qui pré-remplit une « Issue » sur GitHub. Cela permettrait à la communauté de signaler un lien mort sans complexifier l’infrastructure.
- Calculateur d’impact environnemental : Concevoir un algorithme estimant le CO2 évité pour chaque réparation ou recyclage.
- API publique : Ouvrir le catalogue via une API pour que d’autres fablabs puissent intégrer nos données.
Retours utilisateurs
Lors des Sprint Reviews et tests utilisateurs, nous avons reçu des retours encourageants :
« C’est exactement ce dont j’aurais besoin pour préparer mes ateliers ! »
– Fab Manager interrogé
« Le fait de pouvoir filtrer par difficulté me rassure. »
– Professeur de technologie interrogé
Conclusion
MakerLens démontre qu’il est possible de créer une solution numérique utile tout en respectant les principes
low-tech. En agrégeant et standardisant la documentation existante, nous répondons à un besoin réel sans créer
de sur-ingénierie.
Le projet est entièrement open source et peut être forké, modifié et amélioré par la communauté.
Nous espérons qu’il servira de base pour développer des outils similaires dans d’autres domaines (cuisine, jardinage, etc.).
Liens utiles :
- Application : https://promaaa.github.io/maker_lens/
- Code source : https://github.com/promaaa/maker_lens
- Vidéo : https://www.youtube.com/watch?v=mN9q2muRL1g
- Manuel utilisateur : Manuel utilisateur
Projet réalisé dans le cadre du Fil Rouge TAF COUAD 2025 – IMT Atlantique
F.O.C.U.S : Solution technique
SOLUTION TECHNIQUE DU PROJET : F.O.C.U.S.

par LACOTTE Axel, GILLET Lucie, PETIT Gaëtan, Xiaoyu LIU et Gaspard CHEVALIER.
Sommaire
1. Présentation du projet
1.1. Le problème
1.2. Notre solution
2. Évolution du projet
3. Architecture Matérielle
3.1. Le montage électronique
3.2. Composants utilisés
3.3. Le boîtier
4. Architecture Logicielle – Vue d’ensemble
4.1. Les quatre parties logicielles
4.2. Le Frontend – Interface utilisateur
4.2.1. Technologies utilisées (Frontend)
4.2.2. Les trois pages principales
4.3. Le Backend – Serveur
4.3.1. Technologies utilisées (Backend)
4.3.2. Rôle du Backend
4.3.3. Synchronisation avec Taïga
4.3.4. Structure de la base de données
4.4. Le Bootloader et ses services
4.4.1. Qu’est-ce que le Bootloader ?
4.4.2. Séquence de démarrage
4.4.3. Services systemd
4.4.4. Communication via Socket Unix
5. Comment tout fonctionne ensemble
5.1. Parcours utilisateur (Etapes 1 à 6)
5.2. Rafraîchissement automatique
6. Justifications techniques
6.1. Pourquoi Next.js pour le Frontend ?
6.2. Pourquoi Flask pour le Backend ?
6.3. Pourquoi une architecture daemon pour les LEDs ?
6.4. Pourquoi importer depuis Taïga ?
7. Difficultés rencontrées et solutions
7.1. Accès GPIO et privilèges root
7.2. Synchronisation des données
7.3. Affichage multi-zones sur la matrice
8. Perspectives d’amélioration
8.1. Fonctionnalités visuelles
8.2. Aspect ludique et notifications
8.3. Nouveaux Layouts et Support
9. Liens et ressources
1. Présentation du projet
1.1. Le problème
Dans le monde du développement logiciel, les équipes utilisent souvent la méthode agile pour gérer leurs projets. Cette méthode divise le travail en petites tâches, regroupées en user stories, elles-mêmes organisées en sprints. Mais au quotidien, il est difficile de voir où en est le projet dans son ensemble.
Les outils de gestion comme Taiga, Jira ou Trello permettent de suivre les tâches individuellement, mais ils nécessitent d’ouvrir une application, de naviguer dans des menus, et de regarder des chiffres abstraits. La progression du projet reste invisible au jour le jour pour l’équipe menant souvent à une baisse de motivation générale.
1.2. Notre solution
Nous avons créé Focus, un panneau LED physique qui affiche en temps réel la progression d’un projet agile. Placé dans un espace de travail commun, il permet à toute l’équipe de voir instantanément où en est le projet, sans avoir besoin d’ouvrir un logiciel.
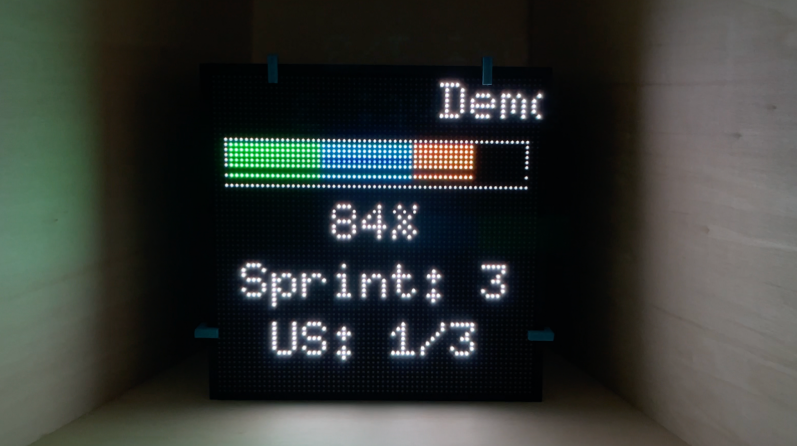
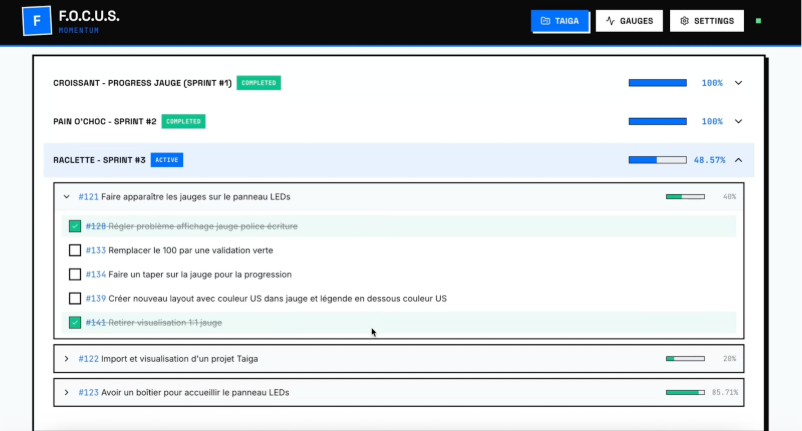
La matrice LED de 64×64 pixels affiche différentes vues :
- Vue globale du projet avec le pourcentage de complétion
- Vue par sprint pour suivre les sprints du projet global
- Vue par sprint pour avoir le détail de ses user stories
2. Évolution du projet
Au début, nous avions l’ambition de créer notre propre outil de gestion de projet complet en plus du panneau LED. Mais nous nous sommes rendu compte que ce n’était pas là où résidait notre valeur ajoutée. Des outils comme Taiga existent déjà et font très bien leur travail.
Nous avons donc recentré notre projet sur ce qui le rend unique : la visualisation physique de la progression. Focus importe les données depuis Taïga et se concentre sur l’affichage, pas sur la gestion. C’est un complément aux outils existants, pas un remplaçant.
3. Architecture Matérielle
3.1. Le montage électronique
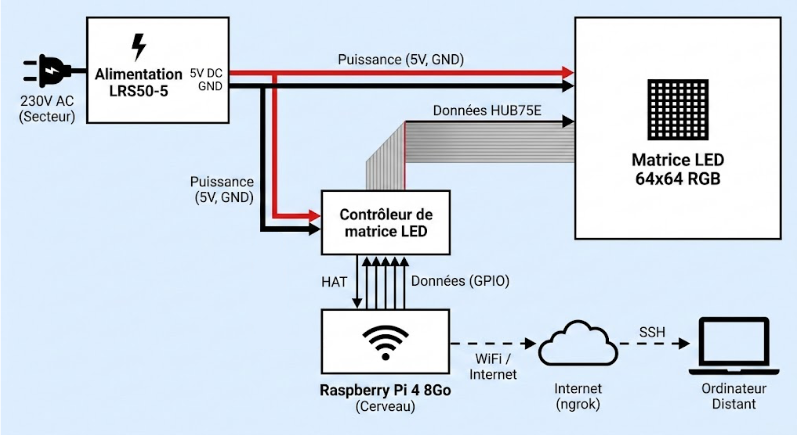
Le système Focus repose sur quatre composants principaux reliés entre eux.
3.2. Composants utilisés
- Alimentation LRS50-5
-
- Lien : gotronic.fr – Alimentation LRS50-5
- Rôle : Convertit le courant secteur (230V) en 5V continu nécessaire pour alimenter la matrice LED. Elle est branchée directement sur une prise secteur.

- Matrice LED 64×64 RGB
-
- Lien : gotronic.fr – Matrice 64×64 à leds RGB
- Rôle : C’est l’écran du système. Elle contient 4096 LEDs (64×64) capables chacune d’afficher n’importe quelle couleur. Elle utilise le protocole HUB75E pour recevoir les données d’affichage.

- Contrôleur de matrice LED
-
- Lien : gotronic.fr – Contrôleur de matrice à leds
- Rôle : Fait le lien entre le Raspberry Pi et la matrice LED. Il traduit les signaux du Raspberry Pi en signaux HUB75E que la matrice peut comprendre.

- Raspberry Pi 4 8Go
-
- Rôle : C’est le cerveau du système. Ce petit ordinateur exécute notre logiciel, se connecte au réseau WiFi, et communique avec Taïga pour récupérer les données du projet.

3.3. Le boîtier
Pour des raisons de sécurité et d’esthétique, nous avons conçu un boîtier en bois découpé au laser. Ce boîtier :
- Cache l’alimentation et les composants internes (on ne voit que la matrice LED).
- Protège les utilisateurs des composants électroniques.
- Donne un aspect professionnel et épuré au produit final.



4. Architecture Logicielle – Vue d’ensemble
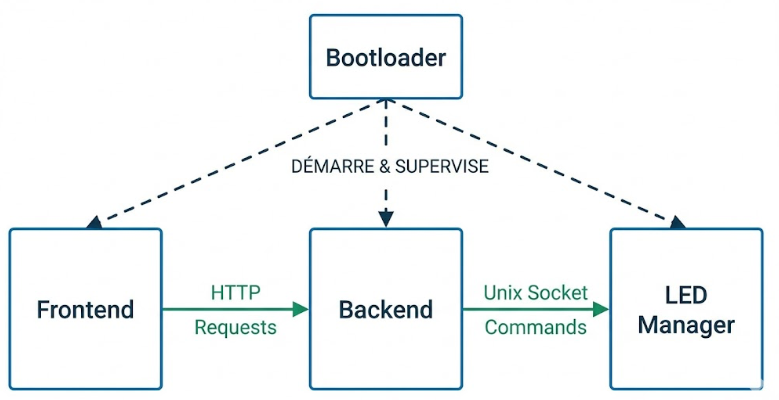
4.1. Les quatre parties logicielles
Le système Focus est composé de quatre parties logicielles qui travaillent ensemble :
- Le Frontend : L’interface web que l’utilisateur voit dans son navigateur. Il permet de se connecter à Taïga et de configurer l’affichage.
- Le Backend : Le serveur qui tourne sur le Raspberry Pi. Il stocke les données, communique avec Taïga, et contrôle les LEDs.
- Le Bootloader : Le système qui démarre automatiquement tous les services quand on allume le Raspberry Pi.
- Le LED Manager : Le service qui contrôle directement la matrice LED, gérant les animations et l’affichage.
Ces quatre parties communiquent entre elles :
- Le Frontend envoie des requêtes au Backend via HTTP.
- Le Backend envoie des commandes au LED Manager via un socket Unix.
- Le Bootloader démarre et supervise tous les autres services.
4.2. Le Frontend – Interface utilisateur
4.2.1. Technologies utilisées (Frontend)
Le Frontend est construit avec :
- Next.js : un framework moderne pour créer des sites web réactifs.
- React : une bibliothèque pour construire des interfaces utilisateur interactives.
- TypeScript : une version améliorée de JavaScript avec vérification des types.
Ces technologies permettent de créer une interface rapide et agréable à utiliser.
4.2.2. Les trois pages principales
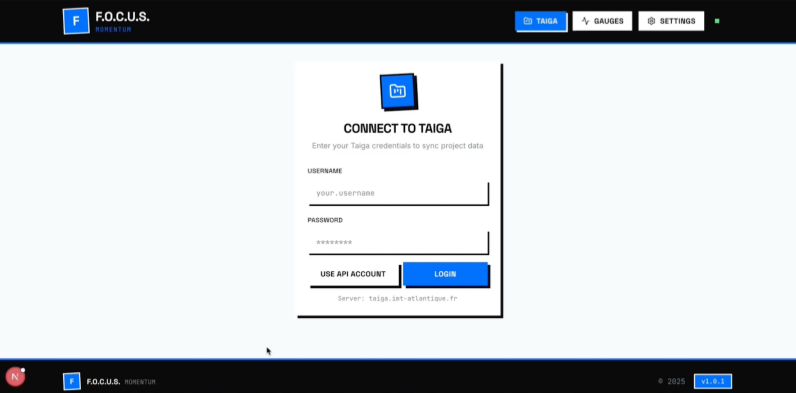
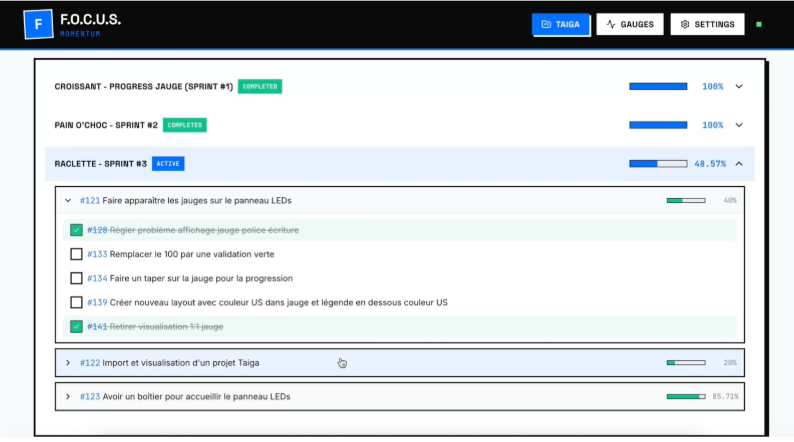
- Page Taiga (page principale)
- C’est là où l’utilisateur se connecte à son compte Taïga et sélectionne le projet à suivre.
- Une fois connecté, il voit l’arborescence complète de son projet : les sprints, les user stories, et les tâches.
- Chaque élément affiche sa progression avec une barre et un pourcentage.
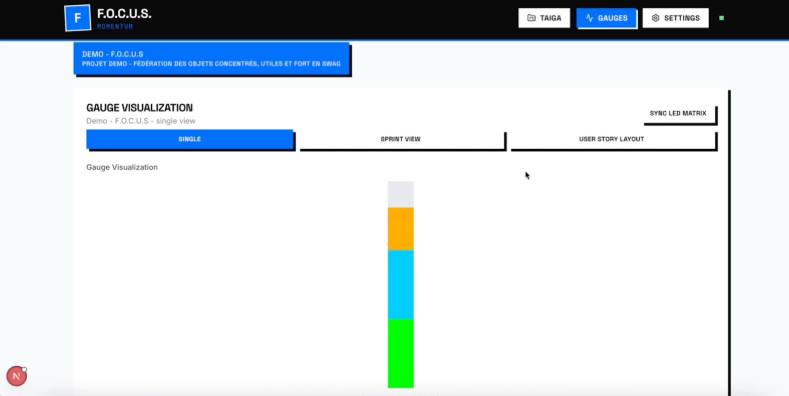
- Page Jauges
- Cette page montre les progressions sous forme de jauges visuelles.
- Elle permet de choisir quel type d’affichage montrer sur la matrice LED : Vue globale (un seul pourcentage), Vue sprint (plusieurs barres), ou Vue user story (détail plus fin).
- Page Settings
- Cette page permet de configurer le rafraîchissement automatique des données, de réinitialiser la base de données si nécessaire, et de voir l’état de connexion du système.
4.3. Le Backend – Serveur
4.3.1. Technologies utilisées (Backend)
Le Backend est construit avec :
- Flask : un framework Python léger pour créer des APIs.
- SQLite : une base de données simple stockée dans un fichier.
- Python : le langage de programmation, choisi pour sa compatibilité avec le Raspberry Pi.
4.3.2. Rôle du Backend
Le Backend est le chef d’orchestre du système. Il :
- Stocke les données du projet dans la base de données.
- Communique avec Taïga pour récupérer les informations via son API.
- Calcule les pourcentages de progression.
- Envoie les commandes à la matrice LED.
4.3.3. Synchronisation avec Taïga
Quand l’utilisateur demande une synchronisation, le Backend :
- Se connecte à l’API Taïga avec les identifiants fournis.
- Récupère la liste des sprints du projet.
- Pour chaque sprint, récupère les user stories.
- Pour chaque user story, récupère les tâches.
- Stocke tout dans la base de données locale.
- Calcule les pourcentages de progression.
- Met à jour l’affichage LED.
L’utilisateur peut aussi configurer un rafraîchissement automatique (toutes les 5 secondes, 2 minutes, ou 5 minutes).
4.3.4. Structure de la base de données
La base de données est organisée de façon hiérarchique :
Projet
└── Sprint 1
└── User Story 1
└── Tache 1 (terminee)
└── Tache 2 (en cours)
└── User Story 2
└── Tache 3 (en cours)
└── Sprint 2
└── …
Le pourcentage de progression est calculé en remontant cette hiérarchie :
- Une tâche terminée = 100%, une tâche en cours = 0%.
- Une user story = moyenne des tâches.
- Un sprint = moyenne des user stories.
- Le projet = moyenne des sprints.
4.4. Le Bootloader et ses services
4.4.1. Qu’est-ce que le Bootloader ?
Quand on branche le Raspberry Pi, il doit automatiquement démarrer tous les services nécessaires. C’est le rôle du Bootloader : orchestrer le démarrage du système.
4.4.2. Séquence de démarrage
Le Bootloader exécute une séquence de 11 étapes, chacune étant signalée par un symbole ou une animation sur la matrice LED :
- Récupération du code (téléchargement des dernières mises à jour depuis GitHub)
- Chargement de la configuration (lecture des paramètres)
- Initialisation des logs (démarrage du système de journalisation)
- Connexion au LED Manager
- Connexion WiFi
- Configuration du tunnel (mise en place de l’accès distant)
- Démarrage du serveur (lancement du Backend Flask)
- Démarrage du Frontend (lancement de l’interface web Next.js)
- Configuration Nginx (mise en place du proxy web)
- Démarrage du bot Discord (activation des notifications)
- Fin du démarrage
4.4.3. Services systemd
Linux utilise systemd pour gérer les services. Nous avons trois services principaux :
- LED Manager Service : Tourne en tant que root (nécessaire pour accéder aux GPIO), contrôle directement la matrice LED et écoute les commandes sur un socket Unix.
- Boot Manager Service : Tourne en tant qu’utilisateur normal, orchestre le démarrage de tous les composants et gère les erreurs et les redémarrages.
- Focus Server Service : Tourne en tant qu’utilisateur normal, exécute le Backend Flask et gère les requêtes de l’interface web.
4.4.4. Communication via Socket Unix
Pour que le Backend (utilisateur normal) puisse contrôler les LEDs (droits root), un socket Unix est utilisé comme canal de communication. Seul le LED Manager a les droits root, ce qui permet de séparer les privilèges et de sécuriser le système.
5. Comment tout fonctionne ensemble
5.1. Parcours utilisateur (Étapes 1 à 6)
Voici le parcours complet quand un utilisateur met à jour une tâche :
- Étape 1 – Connexion : L’utilisateur accède à l’interface web de Focus, entre ses identifiants Taïga et sélectionne son projet.
- Étape 2 – Sélection du projet : Le Frontend envoie une requête au Backend avec les informations du projet. Le Backend se connecte à Taïga.
- Étape 3 – Synchronisation : Le Backend télécharge les sprints, les user stories et les tâches, et les stocke dans la base de données SQLite.
- Étape 4 – Calcul de la progression : Le Backend calcule les pourcentages à chaque niveau de la hiérarchie.
- Étape 5 – Mise à jour de la LED : Le Backend envoie la nouvelle progression au LED Manager via le socket Unix. Le LED Manager la traduit en affichage visuel.
- Étape 6 – Affichage : La matrice LED affiche une barre de progression colorée en fonction du layout sélectionné.

5.2. Rafraîchissement automatique
L’utilisateur peut activer un rafraîchissement automatique (polling). Le Frontend interroge régulièrement le Backend qui re-synchronise avec Taïga. Ainsi, si une tâche est marquée comme terminée dans Taïga, la LED se met à jour automatiquement.
6. Justifications techniques
6.1. Pourquoi Next.js pour le Frontend ?
Next.js offre plusieurs avantages :
- Rendu côté serveur pour des pages qui se chargent rapidement.
- Routing automatique basé sur la structure des fichiers.
- Excellent support de TypeScript.
- Grande communauté et beaucoup de ressources.
6.2. Pourquoi Flask pour le Backend ?
Flask a été choisi car il est :
- Simple à mettre en place, à maintenir et à faire évoluer.
- Très léger.
- Supporté par de nombreuses ressources en ligne.
6.3. Pourquoi une architecture daemon pour les LEDs ?
Le contrôle des GPIO (les broches du Raspberry Pi) nécessite les droits root. Pour des raisons de sécurité, une architecture daemon a été mise en place :
- Un daemon LED Manager tourne avec les droits root (minimum de code).
- Le reste du système fonctionne sans droits root (plus sécurisé).
- La communication rapide et fiable se fait via un socket Unix, permettant aussi de gérer la concurrence entre les services.
6.4. Pourquoi importer depuis Taïga ?
Des outils de gestion de projet comme Taïga sont très aboutis et les recréer n’apporterait pas de valeur. Focus apporte une valeur ajoutée par sa visualisation physique, permettant aux équipes de garder leurs habitudes (Taïga) tout en bénéficiant du panneau LED.
7. Difficultés rencontrées et solutions
7.1. Accès GPIO et privilèges root
- Problème : Le contrôle de la matrice LED nécessite les droits root pour accéder aux GPIO du Raspberry Pi.
- Solution : Architecture daemon avec socket Unix. Le LED Manager tourne en root et les autres services envoient des commandes via ce socket sans avoir besoin des droits root.
7.2. Synchronisation des données
- Problème : Comment garder les données à jour sans bombarder le serveur Taïga de requêtes ?
- Solution : Système de polling configurable. L’utilisateur choisit la fréquence de rafraîchissement (5 secondes, 2 minutes, 5 minutes), avec 2 minutes par défaut comme bon compromis.
7.3. Affichage multi-zones sur la matrice
- Problème : Comment afficher plusieurs informations (sprints, user stories) sur une seule matrice de 64×64 pixels ?
- Solution : Système de layouts configurables :
- Single : une seule grande barre pour le projet.
- Sprint view : plusieurs barres horizontales pour les sprints.
- User story layout : une barre pour le sprint + deux pour les user stories.
8. Perspectives d’amélioration
Avec plus de temps, les ajouts suivants auraient été envisagés :
8.1. Fonctionnalités visuelles
- Jalons visuels : Afficher des marqueurs (lignes à 25%, 50%, 75%) sur la barre de progression pour visualiser les étapes clés.
- Nouveaux layouts : Ajouter un Burndown chart animé.
8.2. Aspect ludique et notifications
- Système de récompenses : Débloquer des badges ou des animations spéciales pour ajouter un aspect ludique et motivant.
- Animations de célébration à 100% : Afficher une animation festive (feux d’artifice, confettis) quand un projet ou un sprint est terminé.
- Notifications sonores : Ajouter un buzzer ou un petit haut-parleur pour émettre un son quand un seuil est atteint (ex: un son encourageant à 50%, feu d’artifice à 100%).
8.3. Nouveaux Layouts et Support
- Support d’autres outils : Étendre la compatibilité au-delà de Taïga pour inclure Jira, Trello et GitHub Projects.
9. Liens et ressources
Dépôt GitHub : https://github.com/stoptexting/couad-focus
Sur ce dépôt, vous trouverez :
- Le code source complet du projet.
- Les instructions d’installation.
- La documentation technique détaillée.
- Les fichiers de configuration pour le Raspberry Pi.
- Les plans de la boite pour la refaire soi-même.
Inauguration de la maquette zone humide
Inauguration de la maquette zone humide
Le 13 novembre dernier, la maquette pédagogique animée représentant une zone humide a été inaugurée dans les locaux de la Maison de l’eau et de la rivière à Sizun. Cette maquette est le fruit de 2 ans de collaboration entre l’IMT Atlantique, notamment via le fablab, le collègue du Val d’Elorn et la Maison de l’eau et de la rivière.
Au début de l’aventure : un besoin exprimé par les élèves de 6ème et leur professeure de SVT de faire une maquette propre et animée pour expliquer le fonctionnement et le caractère remarquable d’une zone humide et des espèces qui y vivent. Cette zone humide, c’est l’Aire terrestre éducative, ou ATE, des élèves : un habitat naturel qu’ils étudient sous toutes les coutures tout au long de l’année. Au programme : observations in situ de traces d’espèces protégées, de plancton, de faune et de flore, rencontre avec des scientifiques et des gestionnaires de zones Natura 2000, fresque du climat mais aussi pose de pièges photographiques et collaboration avec le Muséum d’histoire naturelle pour utiliser des bat box (enregistreurs de chauve-souris). Ce projet extrêmement riche pour les élèves est d’ailleurs financé par un CNR.
Faire une maquette, ce n’est pas si simple, surtout quand elle est animée de lumière et de son… Alors, en lien avec la Maison de l’eau et de la Rivière, les élèves se rapprochent de l’IMT Atlantique. C’est l’occasion pour les élèves de découvrir le Technopôle, le fablab, de visiter le campus mais aussi de venir pêcher et observer du plancton marin pour le comparer avec le plancton observé à Sizun. Et voilà comment nos étudiants de 1ère année ont eu l’opportunité de travaillé sur une maquette illustrant la biodiversité et le fonctionnement d’une zone humide. Un projet DDRS, un projet PRONTO, 2 sorties scolaires à l’IMT Atlantique pour les élèves de 6ème (1 par an), beaucoup de travail au fablab… Et voilà la maquette livrée et inaugurée à la Maison de la Rivière en présence des représentants des élèves de 3ème, 4ème et 5ème ayant participé au projet, du principal du collège, des enseignants, parents, scientifiques.
Un joli moment de partage et de rencontre de tous ces acteurs, tous satisfaits d’avoir collaboré et prêt à recommencer !
 |
 |
Utiliser un module Bluetooth/Série
Le but de cet article est de décrire le fonctionnement et l’utilisation des modules Bluetooth/Série mis à disposition au FabLab. Le but de ces modules est d’offrir une communication similaire à une communication UART (« Serial » dans Arduino), mais en sans fil. Il est donc possible, en utilisant les fonctions standards pour communiquer sur le port série, et avec un effort minimum, de communiquer à distance avec n’importe quel appareil compatible (PC, smartphone, autre module…).
Le principe de ce type de module est quasiment toujours le même, (suite…)
Initiation à la robotique
Prérequis
Arduino
Ardublock
Pour installer Ardublock, il faut télécharger le fichier ardublock.rar. Puis dans le dossier sketchbook de Arduino, créer le dossier tools, puis dedans créer le dossier ArduBlockTool puis dans ce dernier créer le dossier tool (Attention à bien respecter les majuscules et les minuscules lors de la création des dossiers) et coller le fichier ardublock.rar dedans (il faut dézipper le fichier télécharger avant). Lorsque vous lancer Arduino par la suite, une fenêtre vous permet de choisir la version d’Ardublock que vous voulez utiliser.
La version initiation offre les outils nécessaires pour découvrir la programmation Arduino avec Ardublock.
Pour utiliser Ardublock, il faut ensuite dans Arduino cliquer sur Outils puis Ardubloclock.
1) La LED
Objectif
Faire clignoter une LED
Matériel
- une LED de couleur
- une résistance
- un breadboard
- des fils
Montage
Réaliser le montage suivant:
Remarque :
- On peut aussi directement brancher la LED sur la pin 13 car il y a déjà une résistance.
- La LED a un sens, la petite patte est reliée à GND.
Programmation
Voici une capture d’écran du code dans Ardublock pour faire clignoter la LED.
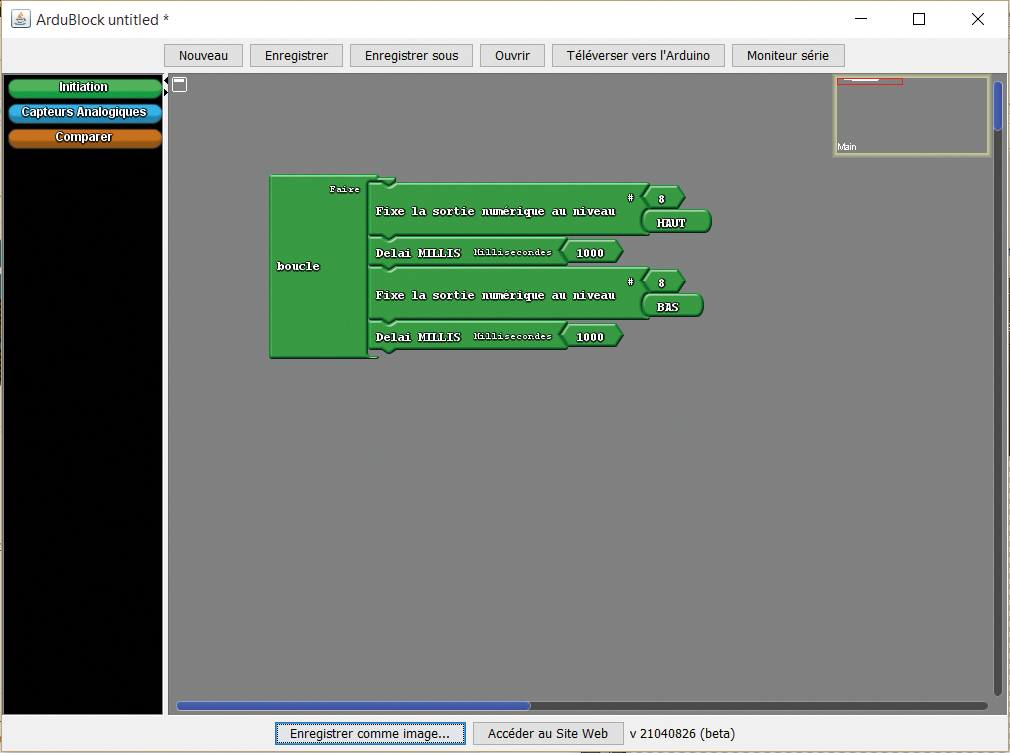
Pour aller plus loin
- Les blocs « délai » permettent au programme de définir la façon dont la LED clignote. Que se passe-t-il lorsque l’on change les valeurs de délai?
- Comment fait-on pour faire clignoter de deux leds de manière indépendantes?
2) Le servomoteur
Objectif
Faire clignoter une LED
Matériel
- un servomoteur 180°
Montage
Réaliser le montage suivant:
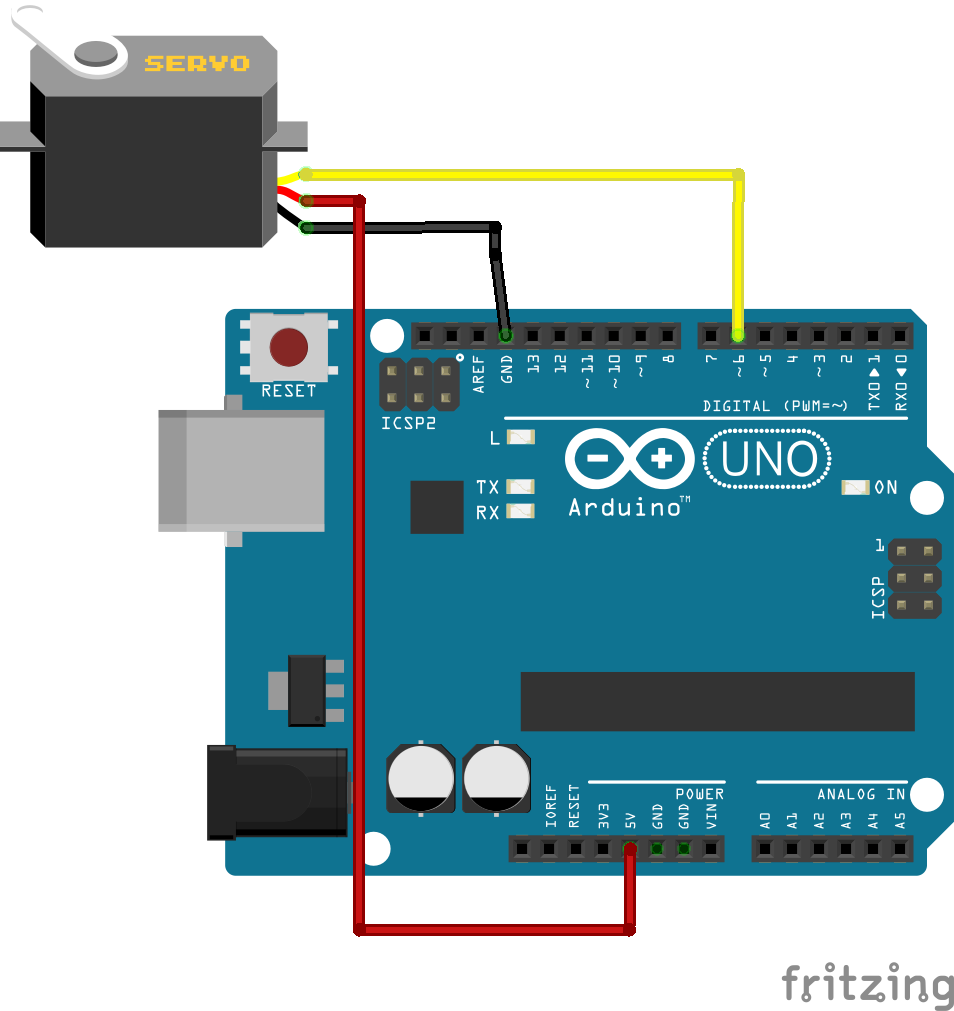
Remarque :
- Le fil le plus sombre correspond généralement à GND, le rouge au 5V, et le troisième fil aux donnés.
- Le fil de données doit être branché sur une pin avec une ~ à côté.
Programmation
Voici une capture d’écran du code dans Ardublock pour faire tourner le servomoteur.
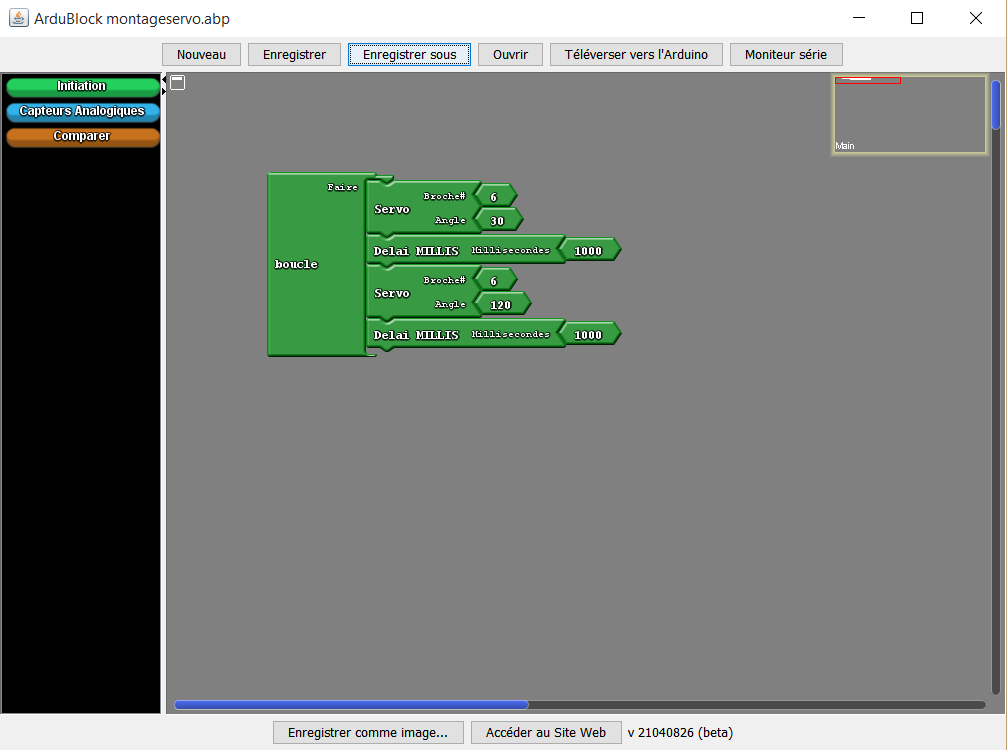
Pour aller plus loin
- Les servomoteurs utilisés peuvent aller de la position 0° à la position 180°. Que se passe-t-il lorsque l’on fait varier la valeur des blocs « delai » et de la valeur angle des blocs « servo »?
- Comment fait-on pour faire clignoter une LED et faire tourner un servomoteur en même temps?
3) Le premier robot
Objectif
Maintenant que l’on a vu comment utiliser un servomoteur et une led, on va réaliser un petit robot chien.
Matériel
- deux servomoteurs 180°
- deux leds
- un breadboard
- des fils
Réalisation du robot

Découper le gabarit

Scotcher les deux servomoteurs ensembles

Assembler le grand parallélépipède (ne pas coller la dernière face)

Mettre les servomoteurs dedans

Assembler la tête et la coller dessus

Mettre les deux leds dans les trous pour les yeux

Coller les deux oreilles et fixer les hélices sur les servomoteurs
Montage
Réaliser le montage suivant:
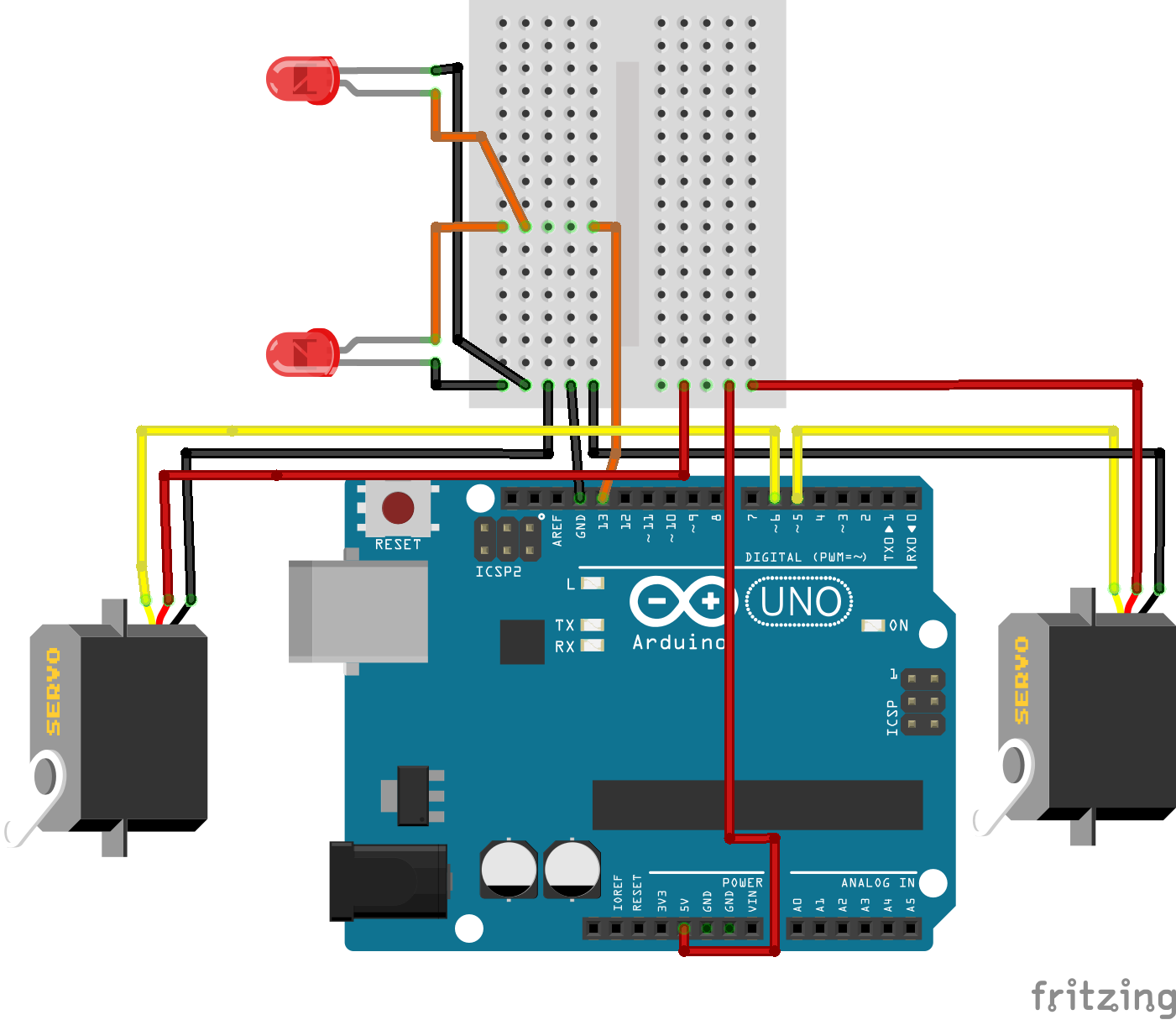
Remarque :
- Les LEDs sont branchés sur la pin 13 pour ne pas avoir à utiliser de résistance.
Programmation
Voici une capture d’écran du code dans Ardublock pour faire bouger le robot.
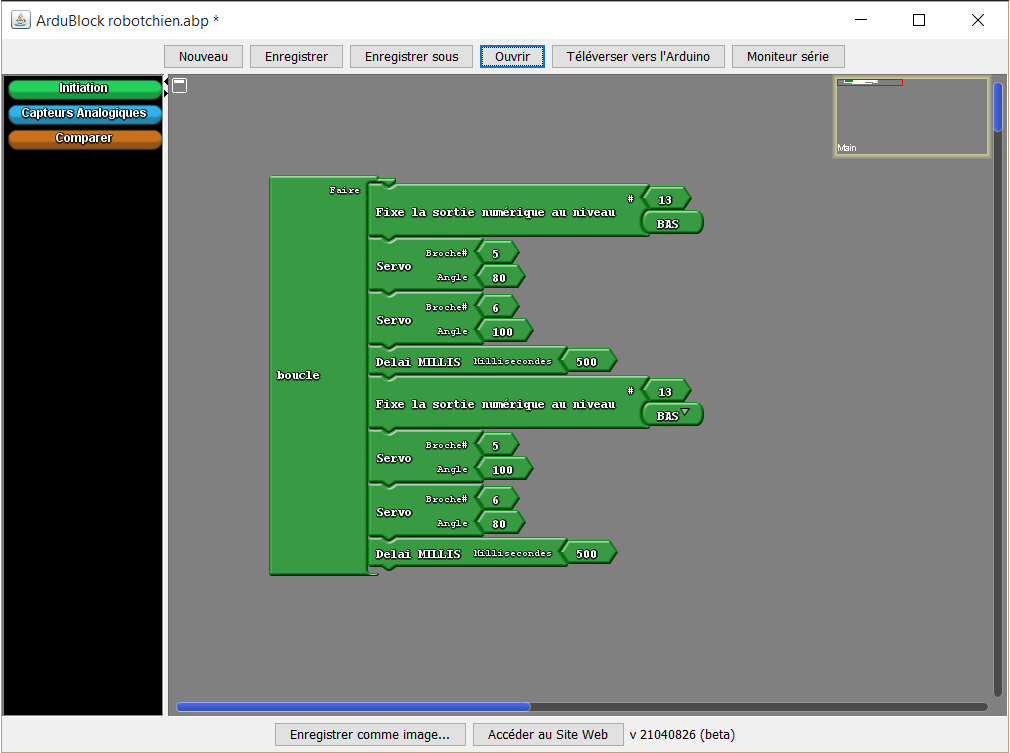
Démonstration
4) Le bouton
Objectif
Détecter quand un bouton est appuyé pour allumer une LED.
Matériel
- une LED
- un bouton poussoir
- une résistance de 10 kΩ
- un breadboard
- des fils
Montage
Réaliser le montage suivant :
Programmation
Voici une capture d’écran du code dans Ardublock pour allumer la LED avec un bouton.
Pour aller plus loin
OBO: Une solution à l’information pertinente sur l’encombrement dans le transport en commun
14/12/2022
Andrés Ricardo CÉSPEDES GARCÍA, Fabrice KOUAME, Daniel Alejandro TERÁN FERNÁNDEZ,
Le transport public est le mode de transport le plus utilisé et le plus populaire en France pour les déplacements dans et hors de la ville. Alors, il y a de nombreux projets pour améliorer les conditions de voyages car les gens peuvent hésiter à l’heure d’utiliser les transports en commun car ils ont des problèmes. Selon la recherche documentaire, on a trouvé que les plus importants problèmes sont le manque de confort [1], la saturation du système [2] et l’incertitude quant à l’état de saturation du prochain service [3]. Ces problèmes de transports publics sont récurrents et doivent être résolus pour inciter davantage de personnes à utiliser les transports publics. Ce projet vise à résoudre un problème réel autour du transport et à répondre à la question :
Comment aider le passager à prendre la décision du choix du véhicule (actuel ou prochain), ainsi que l’entrée dans le véhicule, afin d’améliorer son confort et donc sa satisfaction lors de l’utilisation de ce moyen de transport ?
Ce projet vise à aider à trouver des solutions éco-durables et efficaces pour que les utilisateurs puissent toujours voyager dans le confort.
OBO : Solution technique
On a conçu un système qui permet de donner l’information d’encombrement des prochaines deux services afin que les utilisateurs puissent avoir plusieurs options pour prendre une meilleure décision sur quel service et dans quel wagon entrer dans le système.
Le fonctionnement est basé sur l’usage d’une caméra pour faire la reconnaissance des personnes sur le transport et un affichage pour donner l’information aux usagers. l’idée est que l’utilisateur verra l’affichage et pourra obtenir une pourcentage d’encombrement de chaque wagon, la position de chacun et ainsi, déterminer la position du wagon qu’il est intéressé. La lecture doit être simple et facile à comprendre pour permettre rapidement la prise de décision des utilisateurs.

Fonctionnement détaillé
Il y a trois composantes principales: L’obtention et le traitement de données dans le transport, la communication sans fils et la réception et affichage de l’information. L’architecture du matériel est ci-dessous. À gauche, le système qui est connecté dans le bus qui a la caméra et le processus. On va compter ici le nombre de personnes et obtenir le pourcentage d’encombrement à transmettre par un module ou antenne vers l’arrêt. Donc, Il est nécessaire un module de transmission et un autre de réception pour la communication sans fil; dans ce cas, il est proposé le protocole LoRaWAN. Au moment que l’information est arrivée jusqu’à l’arrêt, le processeur va montrer l’interface d’utilisateur avec l’information pertinente d’encombrement.
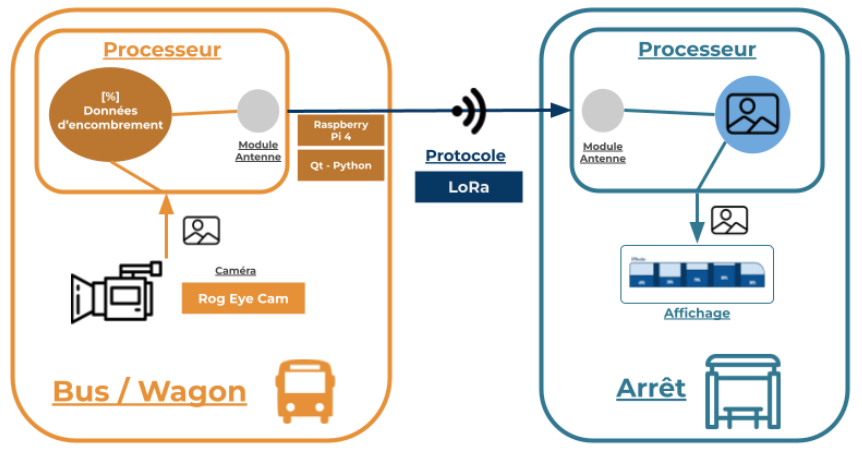
D’une manière simplifiée, le montage réalisé compte avec la reconnaissance des personnes avec la caméra, l’obtention du pourcentage d’encombrement et la création de l’interface dans le raspberry Pi et à la fin, l’affichage.

Reconnaissance d’encombrement
Il y a plusieurs méthodes de reconnaissance d’encombrement avec le traitement des images [4][5][6]. En trouvant la méthode appropriée, on a choisi le reconnaissance des silhouettes des personnes puisqu’il permet d’obtenir un nombre des personnes dans chaque wagon avec un certaine exactitude. Des autres méthodes comme le compteur de personnes qui entrent et sortent et la reconnaissance faciale sont exclus. L’image ci-dessous est un exemple de l’ image et le nombre de silhouettes reconnues avec la caméra [7].

La caméra qui est positionnée dans chaque wagon du transport compte les personnes et les compare avec le nombre maximum permis. Pour ce projet, on a estimé que dans chaque wagon de tramway, il y a maximum 30 personnes dans chaque wagon selon l’enquête de terrain faite et le recherche sur les capacités communes en France. Du coup, on obtient le pourcentage d’encombrement à afficher après.
Affichage de l’information
Tout l’interaction avec l’utilisateur sera à travers de l’affichage. Alors, on a créé une interface en python en utilisant XXX. L’information importante est le nom de l’arrêt, le nom du service, le pourcentage d’encombrement, la symbolisation de l’orientation du transport et la localisation de chaque wagon (en cas du tram ou du métro). L’interface créée est montrée ci-dessous.
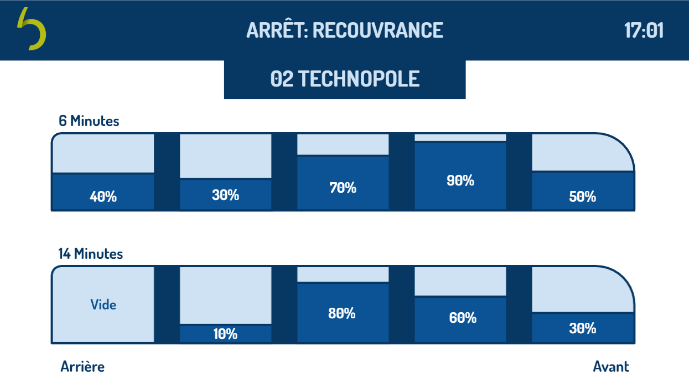
Le image ci-dessus montre comme d’une manière graphique, le remplissage de chaque wagon correspond avec le pourcentage d’encombrement qui va être actualisé à chaque minute.
Montage
Les matériaux nécessaires sont listés ci-dessous.
- Raspberry Pi 3 / 4: Ce processeur a été choisi pour sa accessibilité sur le marché pour faire des prototypages, ainsi comme il est capable de lancer programmes de moyen demande de puissance, puisque l’analyse des images a besoin d’une processus plus fort par rapport à la puissance des autres outils de prototypages. Par exemple, l’usage des cartes Arduino ne sont pas recommandé à cause de sa puissance et les librairies disponibles.

-
- Il convient de rappeler que la raspberry a besoin d’un chargeur d’alimentation 5 V.
- Caméra HD / UHD [Rog Eye Webcam FHD]: Il est nécessaire une caméra avec suffisamment de résolution pour voir les silhouettes des personnes. Il est recommandé d’utiliser une résolution minimum HD (1280 x 720 pixels).

- Écran d’affichage: Il est recommandable de mettre en place un affichage avec une résolution minimum de 800×600 en accord avec l’interface créée. Il faut tenir compte de l’affichage du fournisseur de transport.
- Dans ce lien: https://github.com/andresrcespedes/OBO-CoOC on trouve le dossier OBO-final où on va utiliser le programme “main.py”.
Instructions de montage
- Connecter la caméra et l’affichage au processeur via HDMI et USB. Ci-dessous, l’image qui représente la connexion de la caméra «1» et l’affichage «2»
2. Allumer la Raspberry Pi et lancer le program «main.py » sur le terminal
-
- Pendant le lancement, on peut sélectionner si on utilise la caméra en temps réel (main.py -c true) ou si on utilise des images sauvegardées (main.py -i “IMAGE_PATH”).
- Il est possible de sauvegarder des images si vous voulez dans le même dossier pour les analyser.
Perspectives et travail à futur
Pour continuer ce idée pour ámeliorer l’expérience des usagers sur le transport en commun, il faut concevoir: les connexions de communication à distance entre le bus et l’arrêt, ainsi comme la création d’un database et d’une centre de gestion de dónnées puisque, pour intégrer OBO à une système de transport, il faut que le processeur à l’information de tous les arrêts et des buses ou trames. On recommend travailler avec LoRaWAN pour la communication entre objets.
D’ailleurs, la reconnaissance peut-être tester avec des images obtenus directement des caméras d’un fournisseur réel comme Bibus en Brest, ainsi comme l’interface doit être adapté à chaque ville et les afficheurs utilisés dans la ville.
Les enjeux plus importants seront l’intégration avec les ressources déjà existantes sur les systèmes de transport, ainsi que l’amélioration du système de reconnaissance des personnes, qui a besoin d’un dataset possible de rétroalimentation adapté à chaque système de transport ou il sera implémenté.
References
[1]J. Pel, N. H. Bel, et M. Pieters, « Including passengers’ response to crowding in the Dutch national train passenger assignment model », Transportation Research Part A: Policy and Practice, vol. 66, p. 111‑126, août 2014, doi: 10.1016/j.tra.2014.05.007.
[2]E. O’Toole et N. Christie, « Pregnancy and commuting on public transport », Journal of Transport & Health, vol. 24, p. 101308, mars 2022, doi: 10.1016/j.jth.2021.101308.
[3]M. Kim, S.-P. Hong, S.-J. Ko, et D. Kim, « Does crowding affect the path choice of metro passengers? », Transportation Research Part A: Policy and Practice, vol. 77, p. 292‑304, juill. 2015, doi: 10.1016/j.tra.2015.04.023.
[4] C. Wang and M. Tian, « Passenger Flow Direction Detection for Public Transportation Based on Video, » 2010 International Conference on Multimedia Communications, Hong Kong, 2010, pp. 198-201
[5] Y. Zhang, D. Zhou, S. Chen, S. Gao and Y. Ma, « Single-Image Crowd Counting via Multi-Column Convolutional Neural Network, » 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016, pp. 589-597.
[6] Selvapriya P R, M. Mundada, « IoT Based Bus Transport System in Bangalore », International Journal of Engineering and Technical Research (IJETR), février 2015
[7] David Sepúlveda. People Counting Systems with OpenCV, Python, and Ubidots Ubidots. Checked the 15/12/22.
