
Réalisation d’un distributeur de cocktails automatisé, contrôlé par une application via Bluetooth et doté d’une interface utilisateur conviviale. L’utilisateur sélectionne le cocktail souhaité à travers l’application. Un prototype fonctionnel a été développé l’année précédente, tandis que cette année, l’objectif consistait à concevoir un modèle 3D de la machine afin de construire un châssis capable d’accueillir tous les composants. Par ailleurs, l’application offre des fonctionnalités attrayantes pour les utilisateurs, telles que l’ajout de nouveaux cocktails pour les administrateurs, l’accès à une base de données de cocktails et bien d’autres avantages.
Accueil de 100 collégiens
Cette année les 100 élèves de 3ème du collège Victor Daubié qui ont la chance d’avoir Mr Jaouen comme professeur de technologie participent à nouveau à leur compétition de robots.
Au programme du mardi 11 avril matin :
Visite du campus pour découvrir ce qu’est un Technopôle et une école d’ingénieur avec leur professeur d’Histoire-géographie, découverte du fablab, assemblage des composants électroniques et découpe des châssis de robot !
Un grand merci encore aux étudiants et aux collègues ayant assuré les 4 visites de site pendant que je gérais le fablab !

Quelques mois plus tard, voici les robots finalistes de la compétition
Merite en CM2 à Bourg-Blanc
Pour déployer un réseau de relais d’animateurs des mallettes MERITE, il faut passer par des personnes clés. Les conseillers pédagogiques en font partie : ces anciens professeurs accompagnent leurs collègues dans les classes sur des projets pédagogiques.
Maud Tournery a donc animé un projet de phare avec les CM2 de l’école publique du Bourg-Blanc avec Armande Péres, conseillère pédagogiques sciences pour le Finistère. L’occasion pour Armande de bien comprendre l’esprit des mallettes, de s’y former et donc de mieux la « vendre » à ses collègues.
En moins d’une journée cumulée, les élèves ont appris suffisamment de programmation graphique pour pouvoir faire clignoter deux DELs en haut d’un phare réinvestissant tout leur travail d’arts plastiques de l’année et pour faire tourner un poisson grâce à un servomoteur. Très investis, les élèves étaient étonnant d’assiduité ! Imaginez 24 élèves qui reviennent de récréation et se remettent à programmer et à faire leurs montages électroniques sans attendre le retour de la maitresse…

Au milieu le phare construit au fablab pour amorcer le projet, à droite la réalisation des élèves

Un terrible suspens dans les dernières 40 min du projet pour assembler notre montage électronique dans le phare ! Chaque élève a participé au montage et tout a marché : ouf !
Un cubsat au téléfab
A l’occasion du lancement officiel d’IRISPACE, l’Institut Régional de l’Innovation Spatiale le 23 juin 2023, une maquette d’un CubeSat a été réalisée au fablab.
Les CubeSat sont des satellites cubiques miniatures (10 cm × 10 cm × 10 cm – à peu près la taille d’un cube Rubik) qui pèsent environ 1 kg . Un CubeSat peut être utilisé seul (1 unité) ou en groupe (jusqu’à 24 unités).
Différentes machines et matériaux ont été utilisés :
– impression 3D pour les éléments replissant le CubeSat,
– panneaux solaires à la découpeuse laser (contreplaqué peuplier peints en noir, cellules photovoltaïques en matériau spécial, charnières)
– plaques de plexiglas pour les parois du CubeSat (pour voir à l’intérieur), fixée avec des scratchs adhésifs et des tiges en métal pour allier robustesse, facilité de démontage et de manipulation.


à gauche : Le CubeSat fermé, à droite : un des panneaux solaires est déployé.
Forum des codevsi 2023
Cette année encore une soutenance spéciale pour les projets tournant au tour du fablab a eu lieu !
Au programme des démonstrations :
prototype de drone sous-marin, caméra sous-marine open source KOSMOS, mangeoire connectée, système d’arrosage automatique de plante de laboratoire, amplificateur de guitare, atelier de pilotage de drone testée en collège ou encore prototypage de tapis de multiplication connectée !






Capteur de CO2 : de la TAF CoOC au lycée
Cette année, la mallette MERITE « objets animés » a servi en classe de seconde, au Lycée de l’Iroise, pour un projet test. L’objectif du projet ? Accompagner les lycéens pour qu’ils se mettent à la place d’un ingénieur et développent un capteur de C02 en 4 séances.
Le capteur de CO2 initial a été créé en TAF CoOC (un enseignement de spécialité sur les objets connectés dans notre école d’ingénieurs) en 2021. Durant 4 séances, les lycéens ont réfléchi au design et à l’usage de leur capteur, revu la programmation en blocs sur Ardublock, réfléchi à leur montage électronique et aux options de leur capteur.
Le design a bien sûr été revu et adapté en cours de projet, une première fois pour s’adapter au montage des composants électroniques puis avec le prototype en carton. La 4ème et dernière séance a eu lieu au fablab en fin d’année : au programme soudure, découpe laser et assemblage ! 4 salles du lycée seront ainsi équipées d’un capteur de CO2 permettant de signaler la nécessité d’aérer la salle. Les designs vont du simple cadran avec une aiguille qui tourne, à une lampe très esthétique, en passant par une fusée (avec un silhouette mobile), une plante et un talkie-walkie.




des prototypes en cartons… à l’assemblage au fablab !

Fichiers pdf des designs imaginés par les élèves :
Un diaporama a été utilisé pour guider les séances, de même que la mallette MERITE « objets animés« .
Course de drone au collège
Dans le cadre de leur projet CODEVSI, Hugo Dhers, Moustapha Mbaye et Antoine Carré ont animé un atelier de 2h au collège Victoire Daubié.
Programmation de drone, apprentissage du pilotage puis course de drones étaient au programme pour la classe de 4ème concerné.

Moustapha était au stand programmation avec de jolis défis


Voire réparait les drones après des chocs… Ces drones s’arrêtent au moindre choc et partent parfois en pièces détachées, un gros atout pour la sécurité des usagers lors de ce type d’utilisation en public !
Afin de faciliter la prise en main des drones par les collégiens, nos 2 étudiants ont produit des documents pédagogiques :
Les Trophées
Des trophées sont régulièrement fabriqués au fablab en différents bois, PMMA (plastique), mélange des deux, avec colle, sans colle, avec gravure etc.
Les 1er prix du Trophée vidéo

Un trophée pour la Bapav (vélo à Brest) avec une belle originalité dans la conception : le pont de recouvrance en plexiglas, le spiles de pont et les silhouettes en vélo en CP peuplier.

Le trophée SARA pour les navigateurs malvoyants en plexiglas et texturé.

Un des trophées du Global Village 2024 : les couverts et les lettres « global village » sont en MDF 3mm gravés, l’assiette est en CP peuplier 3mm, le globe terrestre est en MDF. Le trophée est recto-verso : on peut choisir la face à exposer en fonction de l’origine géographique du vainqueur. Le socle est doublé (2x3mm) pour compenser le poids.


Atelier upcycling de chemise
Que faire avec nos vieilles chemises ?
Manuelle Fauvel d’Act’Iroise est venue au fablab nous apprendre à faire des tote-bags, des hauts, des pochons et même un tablier pour le fablab. De quoi protéger les usagers qui viennent en tenue estivale !
Un moment convivial, avec beaucoup de bonne humeur et de concentration entre fabrication de biais maison, découverte de la surjeteuse et des points à l’envers…


Bravo aux couturières en herbe !

Les lycéennes en visite à ce moment là ont été intriguées : c’est aussi ça un fablab !

Découverte de la KOSMOS
Cette année, 3 étudiants de 1ère année assemblent et testent la documentation de la KOSMOS, une caméra sous-marine open source créé au Konk-ar-lab (le fablab de Concarneau) et l’Ifremer.
Comme tout projet collaboratif et open source, la documentation présente des bugs, des imprécisions bref toute une série de petites (et moins petites) imperfections qu’il est précieux de corriger et de faire remonter à l’équipe projet.
Après un mois de rédaction de cahiers des charges fonctionnel et 2 semaines de prise en main du sujet, notre dream team a enfin mis les mains dans le cambouis et commencé à assembler, nettoyer le support des pièces imprimées à l’imprimante 3D, visser sur les supports découpés à la découpeuse laser, souder (avec une montée en compétence fulgurante !).
Jeudi 13 avril, c’était l’occasion de rencontrer l’équipe projet avec des membres de l’Ifremer, du Konk-ar-lab, et les étudiants de l’ENIB qui travaillent sur le même projet.

Si ce projet est pour l’instant un projet de 1ère année, il a vocation à être continuer dans les années supérieures et intégré à une dynamique de projets de sciences participatives.
Un challenge dans un futur pas si lointain ? Tester si la KOSMOS peut être déployé sur un monocoque comme notre POGO…
Robotise
I – Introduction
-
But du projet (et les domaines / technologies qu’il couvre)
-
Spécifications du projet
Diagramme de cas d’utilisation :
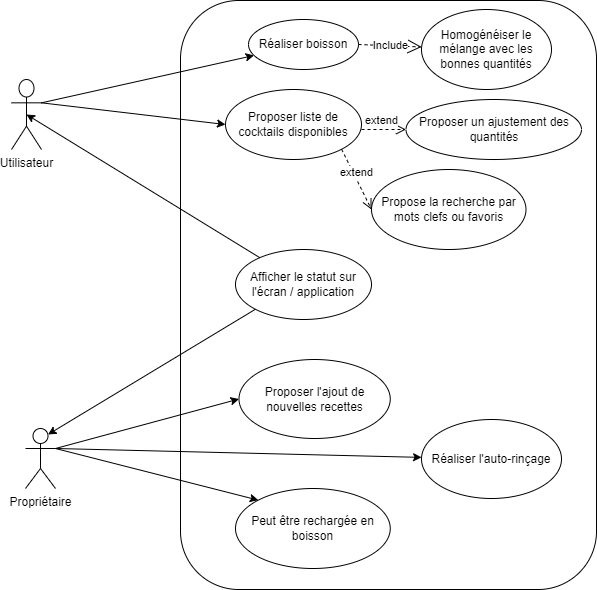
Diagramme de blocs d’architecture :
Ce diagramme offre une vue d’ensemble de la conception de la machine et des diverses interconnexions qui la composent. Il présente les flux de données entre la carte de contrôle de la machine et l’application utilisateur, les flux énergétiques entre les différents éléments de la carte mère et le Raspberry Pi, ainsi que les flux de liquides entre les réservoirs d’entrée et la sortie du bec verseur.
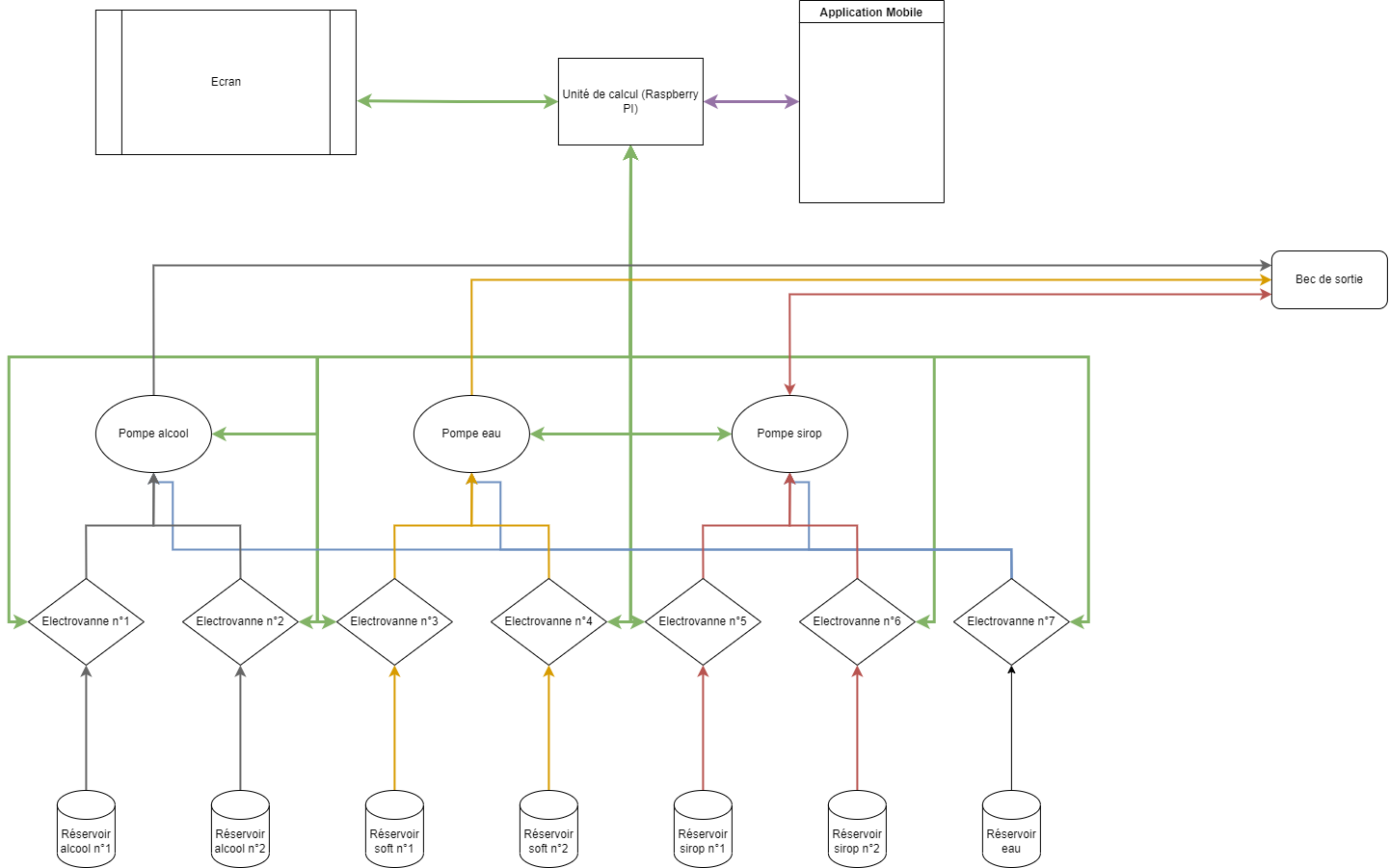
En résumé, ce schéma permet de visualiser clairement les interactions entre les éléments clés du système, mettant en lumière les échanges de données, d’énergie et de liquides qui rendent possible le fonctionnement harmonieux de la machine à cocktails.
II- Hardware
-
Conception 3D
Liste nécessaire pour impression 3D :
- 3 raccords G1/2” femelle vers cannelé 8mm par ligne hydraulique (2 pour l’électrovanne et 1 pour le débitmètre)
- Mux 2 entrées vers 1 sortie pour raccorder 2 lignes ensemble
- 1 raccord G1/2” mâle vers cannelé 8mm par ligne hydraulique (pour le débitmètre)
Voici une représentation 3D de ces 3 éléments dans le même ordre que cité ci-dessus:
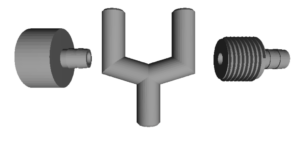
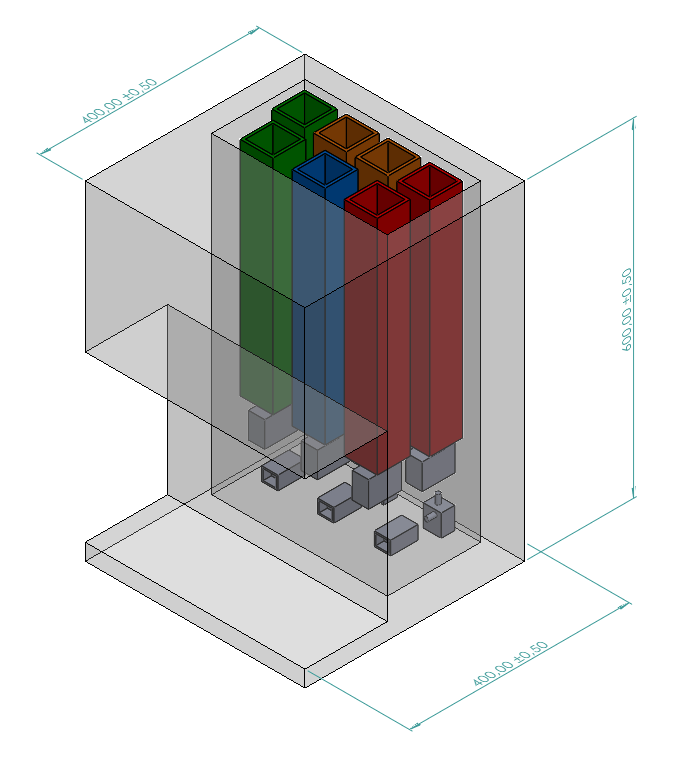
Voici une représentation 3D du châssis qui fait entre 40cm et 60cm :
-
Électronique embarquée
Liste matériel pour configuration 7 réservoirs (2 sirops, 2 jus, 2 alcools et 1 eau) :
- 10 transistors NPN (ici BD241C de ST)
- 10 résistances de 10 ohms
- 7 électrovannes 12V
- 3 débitmètres (ref: YF-B2)
- 3 pompes 12V
- 1 alimentation 240V~ – 5V / 12V (ref: RD65A)
- Flexibles
- Raspberry PI 3B+
L’objectif ici est de concevoir la partie esclave de la machine, qui sera pilotée via l’application utilisateur. La carte de contrôle (en l’occurrence, le Raspberry Pi 3B+) sera responsable de la gestion des différents composants de la machine grâce à ses broches GPIO. Étant donné que la machine doit être capable de fournir diverses boissons à l’utilisateur, il est nécessaire d’ajouter des signaux de contrôle à la partie matérielle. Ces signaux contrôleront les grilles des transistors pour les rendre conducteurs ou non, en fonction du composant à alimenter (pompe et/ou électrovanne).
Un autre aspect crucial est le contrôle du volume de liquide versé par le système. À cet effet, des débitmètres sont installés sur chaque conduite hydraulique reliée à la sortie de chaque pompe, permettant de surveiller en temps réel le volume de chaque liquide versé. Ces débitmètres sont des capteurs à effet Hall qui envoient des impulsions au Raspberry Pi lorsqu’ils détectent un liquide dans la conduite. Le Raspberry Pi est alors chargé du traitement des données et de la gestion du débit des pompes pour délivrer le volume de liquide demandé.
Le schéma électrique ci-dessous, implémenté sur une carte PCB, présente le Raspberry Pi sur la droite, représenté par ses broches GPIO, ainsi que la carte mère de la machine, avec les composants alimentés en 5V ou 12V. On y distingue également les signaux de contrôle des transistors et les signaux de retour d’information des débitmètres.
Schéma PCB :

La disposition finale choisie est présentée ci-après, sans les connexions filaires pour plus de clarté :
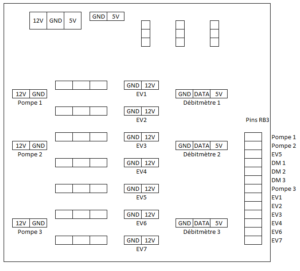
Pour résumer simplement la configuration d’une ligne de base du circuit hydraulique, voici l’ordre à suivre : Réservoir -> Électrovanne -> Pompe -> Débitmètre -> Bec de sortie. La séquence de distribution d’un liquide se déroule comme suit : l’électrovanne associée à un réservoir s’ouvre, puis la pompe s’active. Le volume de liquide versé est mesuré par le débitmètre, et une fois le volume souhaité atteint, la pompe se désactive et l’électrovanne se ferme.
Afin de réaliser des économies, deux lignes peuvent être combinées pour utiliser une seule pompe et un seul débitmètre pour deux réservoirs différents. Il est donc nécessaire de relier les deux lignes ensemble après les électrovannes en utilisant un multiplexeur (Mux) à deux entrées et une sortie, qui sera connectée à la pompe unique.
III – Software
-
Application mobile
Fonctionnalités
Cette application a de multiples fonctionnalités:
– Elle permet à l’utilisateur de choisir un cocktail à commander
– Elle permet à l’administrateur de mettre à jour les cocktails de l’application par rapport à la base de données
– Elle permet à l’administrateur de mettre à jour les ingrédients et leurs quantités dans la base de données
– Elle permet à l’utilisateur d’avoir des cocktails favoris
Déroulement de l’application
Dans un premier temps, l’utilisateur doit accepter deux permissions: l’accès au Bluetooth et l’accès à la position.
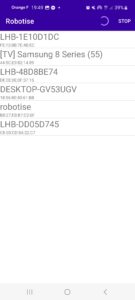
Ensuite, la configuration BLE (Bluetooth Low Energy) est indispensable. L’application affiche une liste des appareils Bluetooth Low Energy disponibles. À ce stade, il suffit de choisir l’appareil portant le nom « robotise » ou « rpi-gatt-server ».
Lorsque l’appareil est sélectionné, un service est créé pour gérer le Bluetooth du téléphone. Si l’appareil se déconnecte du BLE pour une raison quelconque, la méthode onServiceDisconnected sera appelée.
Une fois le service Bluetooth activé, un autre service est créé dans le but de gérer la connexion et la communication entre les deux éléments. Ce service se connecte alors à l’appareil Raspberry Pi et récupère le serveur GATT du Raspberry. L’application communique avec le service, qui à son tour communique avec l’API Bluetooth LE.
L’implémentation BLE a été fortement inspirée d’un projet existant : Bluetooth LE GATT.
Pour que cela fonctionne correctement, les caractéristiques suivantes doivent être présentes dans le service :
- CommanderCocktailCharacteristic : la caractéristique permettant d’envoyer une commande de cocktail.
- BDRecettesCharacteristic : la caractéristique permettant de recevoir la liste des recettes de cocktails.
- BDIngredientsCharacteristic : la caractéristique permettant de recevoir la liste des ingrédients présents dans la base de données.
- MajIngredientsCharacteristic : la caractéristique permettant de mettre à jour les ingrédients disponibles dans la machine dans la base de données.
- AddCocktailCharacteristic : la caractéristique permettant d’ajouter un cocktail à la base de données.
- DeleteCocktailCharacteristic : la caractéristique permettant de supprimer un cocktail de la base de données.
- AjouterIngredientCharacteristic : la caractéristique permettant d’ajouter un ingrédient à la base de données.
- DeleteIngredientCharacteristic : la caractéristique permettant de supprimer un ingrédient de la base de données.
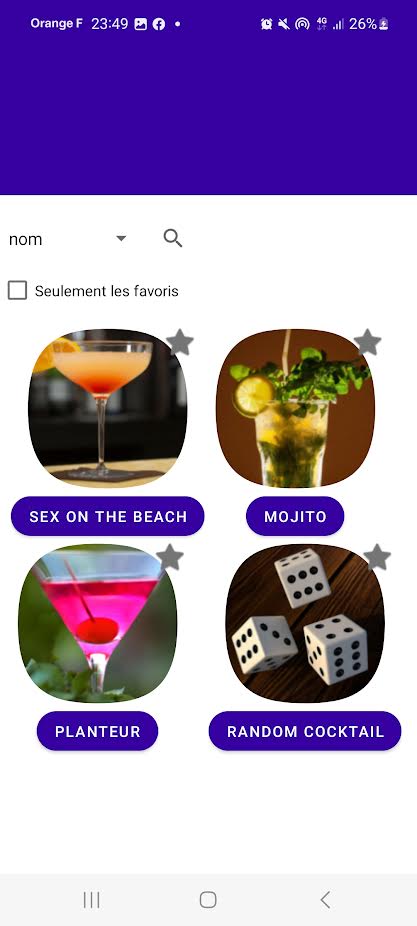
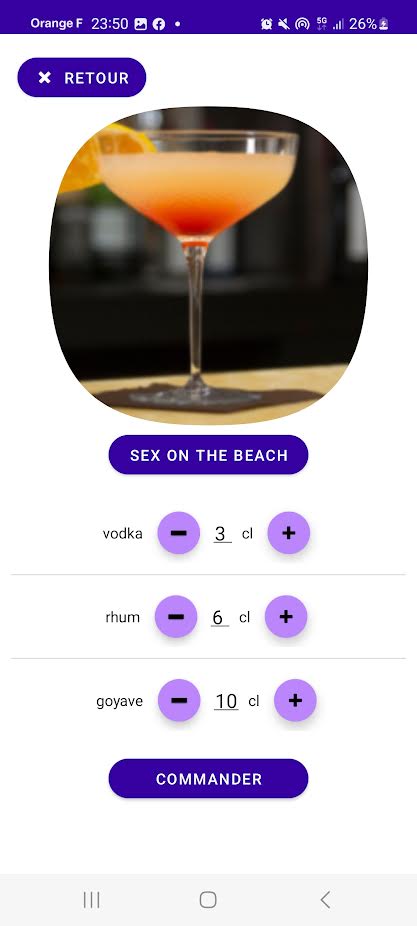
Pour l’instant, l’utilisateur a accès à une seule fonctionnalité : commander un cocktail. Lors de la connexion, la fenêtre ListCocktailsActivity s’ouvre, permettant à l’utilisateur de visualiser la liste des cocktails disponibles. Cette liste est gérée par la classe CocktailListView. Chaque cocktail est représenté par la classe CocktailItem, et son affichage est contrôlé par la classe CocktailsArrayAdapter. En cliquant sur un cocktail, une page s’ouvre (PopUpCocktail), affichant la composition du cocktail.
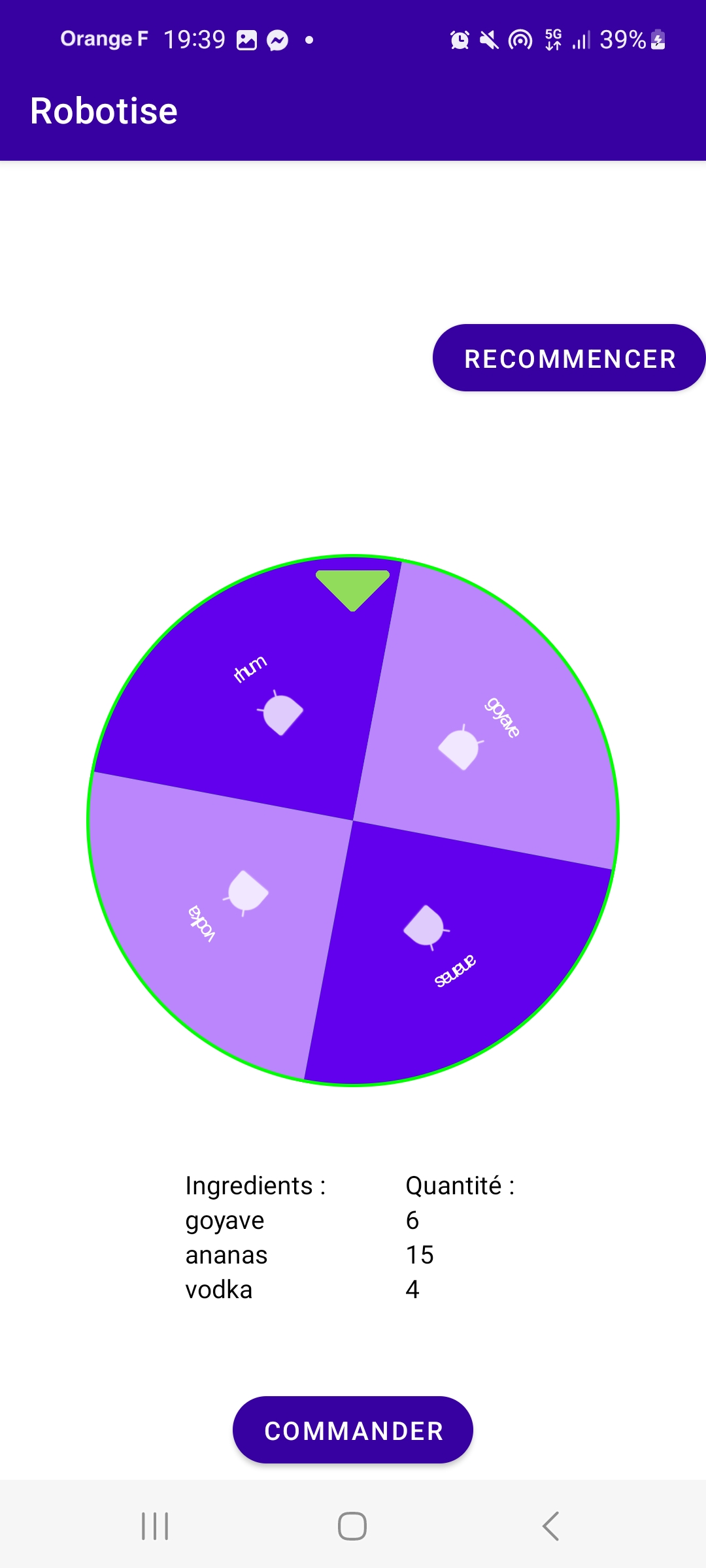
Chaque ingrédient est représenté par la classe IngredientItem, et son affichage est géré par la classe IngredientArrayAdapter. L’utilisateur peut modifier les quantités de chaque ingrédient avant d’appuyer sur le bouton « commander ». Il a également la possibilité de choisir un cocktail aléatoire grâce à la classe WheelActivity. L’utilisateur peut faire tourner une roue trois fois, et à chaque tour, un ingrédient sera sélectionné avec une quantité aléatoire attribuée. Ce processus permet de créer un cocktail aléatoire à partir des ingrédients disponibles.
Après avoir commandé son cocktail, l’utilisateur a la possibilité de jouer en duo au morpion en attendant que son cocktail soit prêt. Une fois le cocktail terminé, l’utilisateur recevra une notification.
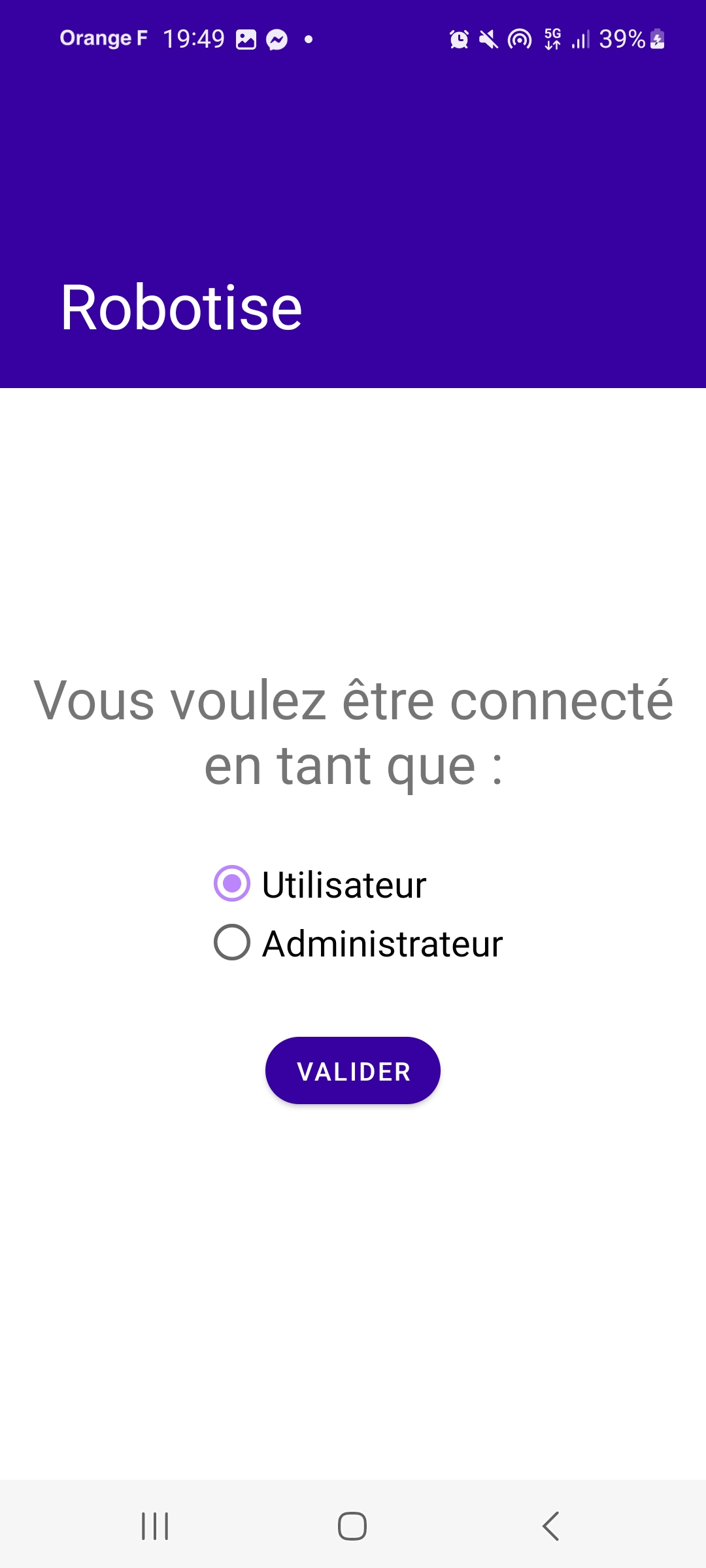
De son côté, l’administrateur doit entrer un mot de passe pour se connecter. Pour l’instant, le mot de passe est « hello » et est codé en dur dans l’application. À l’avenir, il serait préférable d’utiliser une méthode de stockage et de vérification de mot de passe plus sécurisée.
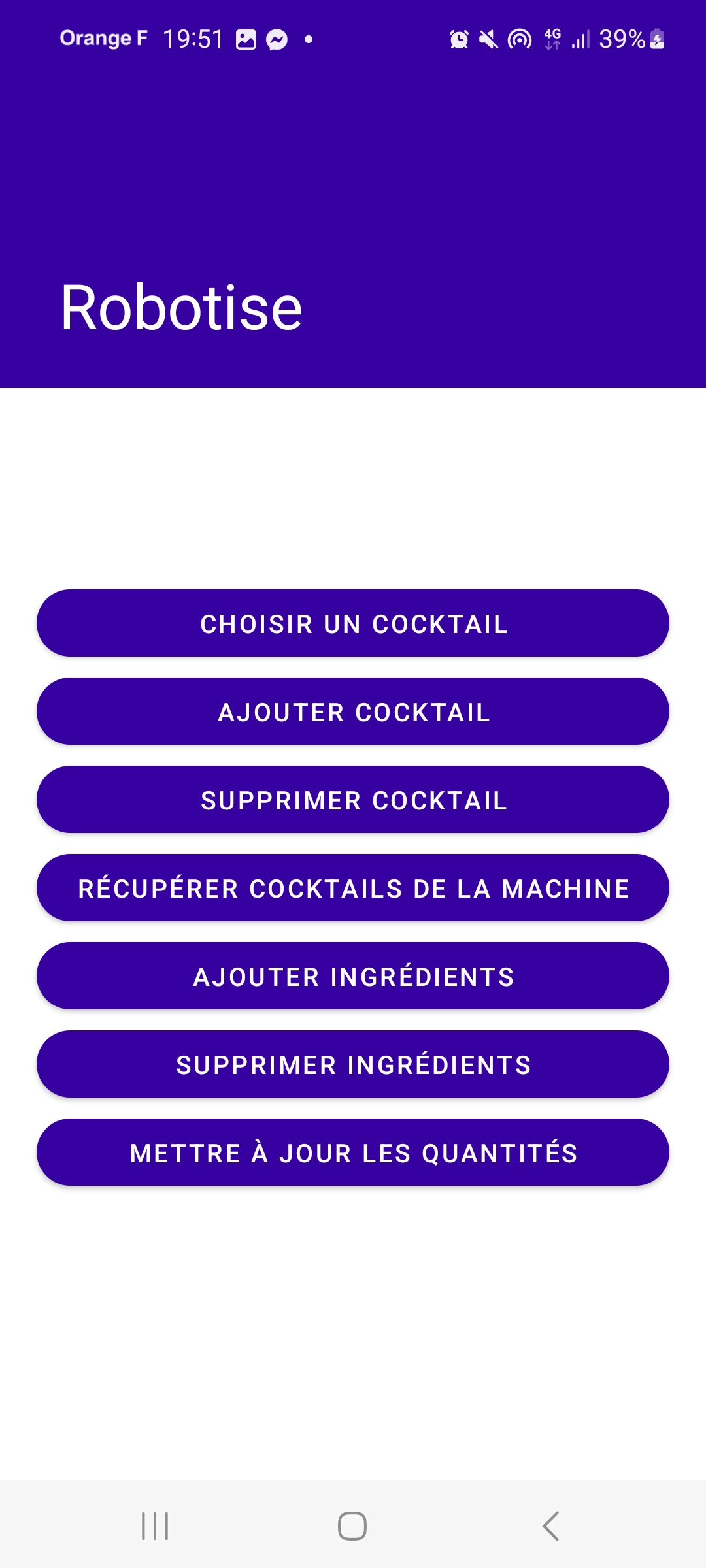 Après s’être connecté, la fenêtre AdminActivity s’ouvre et l’administrateur dispose de plusieurs fonctionnalités. Il peut :
Après s’être connecté, la fenêtre AdminActivity s’ouvre et l’administrateur dispose de plusieurs fonctionnalités. Il peut :
-
-
-
-
- Choisir un cocktail à commander, tout comme l’utilisateur.
- Ajouter ou supprimer un cocktail.
- Ajouter ou supprimer un ingrédient.
- Mettre à jour les quantités de chaque ingrédient disponible dans la machine.
- Récupérer la liste des cocktails proposés par la machine.
-
-
-
Ces options offrent à l’administrateur un contrôle complet sur les cocktails et les ingrédients disponibles, ainsi que sur la gestion des stocks de la machine.
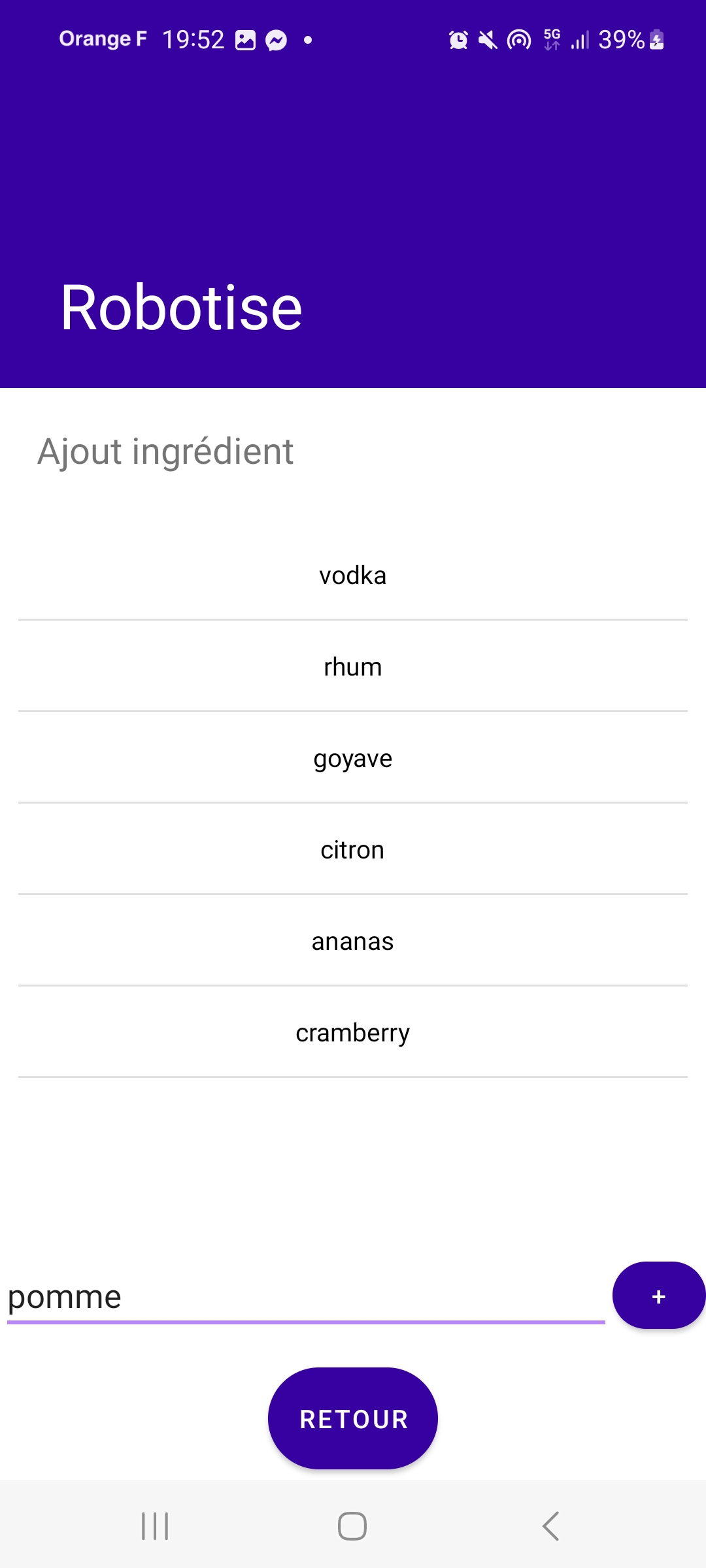 Si l’administrateur choisit l’option « ajouter un ingrédient », une nouvelle fenêtre s’ouvre : AdminAddIngredientActivity. La liste des ingrédients est chargée depuis la base de données. L’administrateur a ensuite la possibilité d’ajouter un ingrédient. Cet ingrédient sera envoyé via Bluetooth Low Energy (BLE) à la base de données du Raspberry Pi. Enfin, la liste des ingrédients mise à jour est renvoyée du Raspberry Pi vers le téléphone de l’administrateur.
Si l’administrateur choisit l’option « ajouter un ingrédient », une nouvelle fenêtre s’ouvre : AdminAddIngredientActivity. La liste des ingrédients est chargée depuis la base de données. L’administrateur a ensuite la possibilité d’ajouter un ingrédient. Cet ingrédient sera envoyé via Bluetooth Low Energy (BLE) à la base de données du Raspberry Pi. Enfin, la liste des ingrédients mise à jour est renvoyée du Raspberry Pi vers le téléphone de l’administrateur.
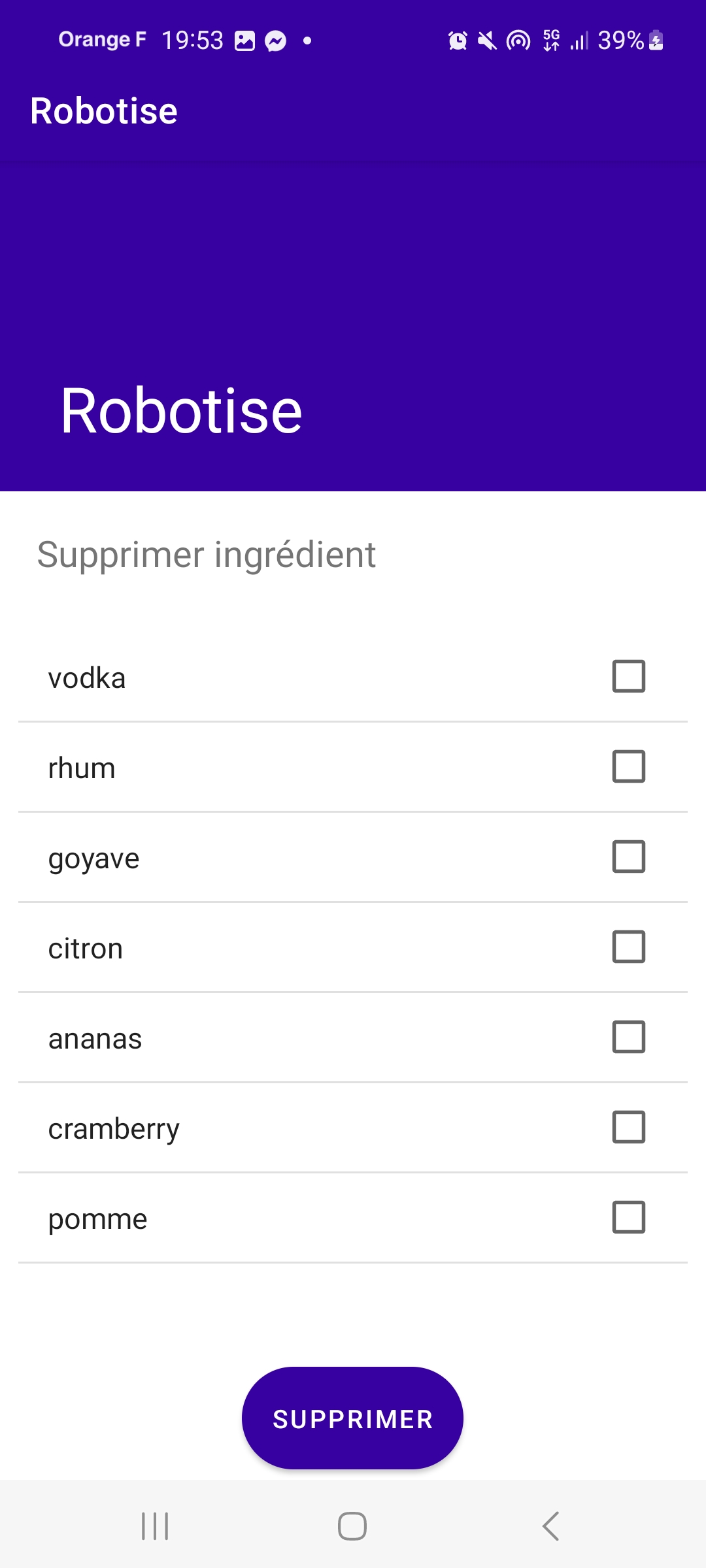
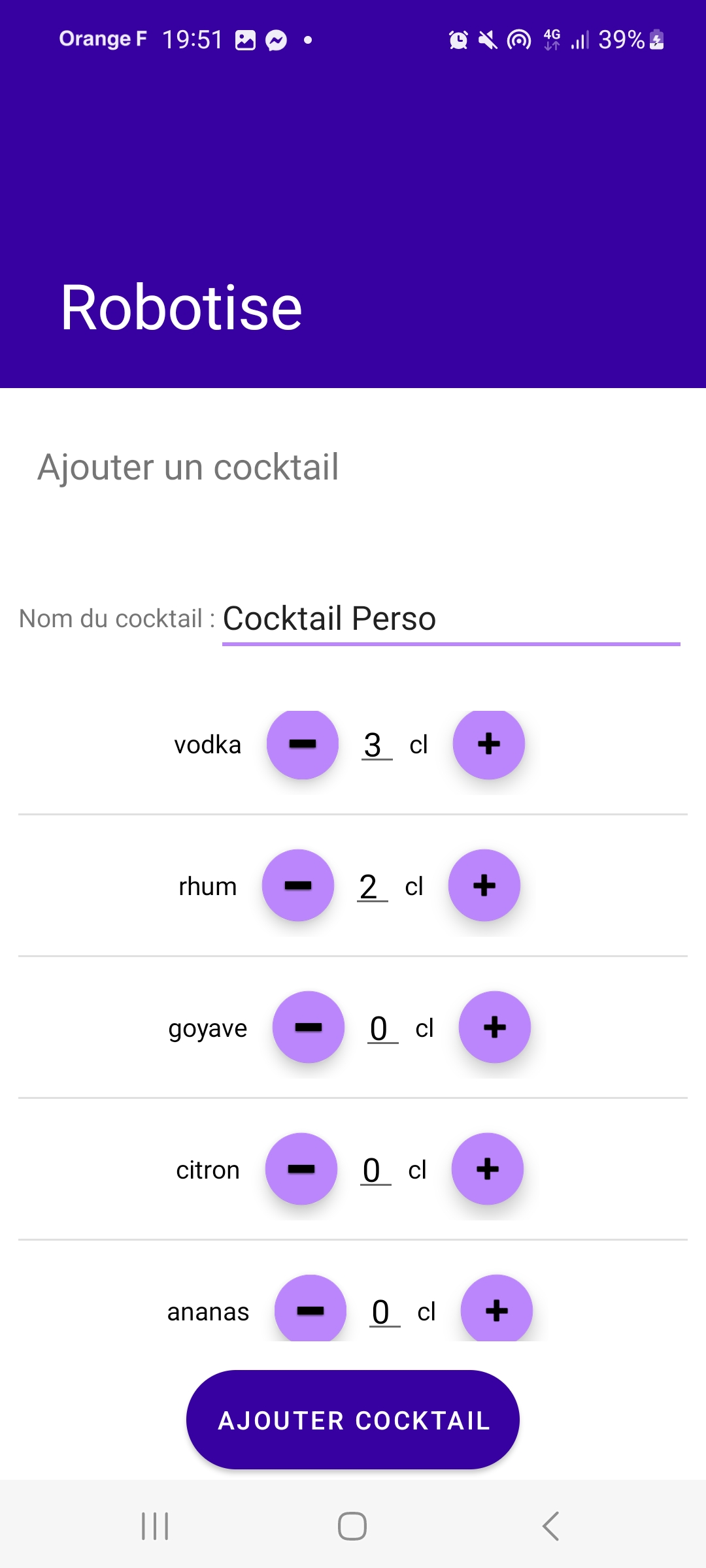
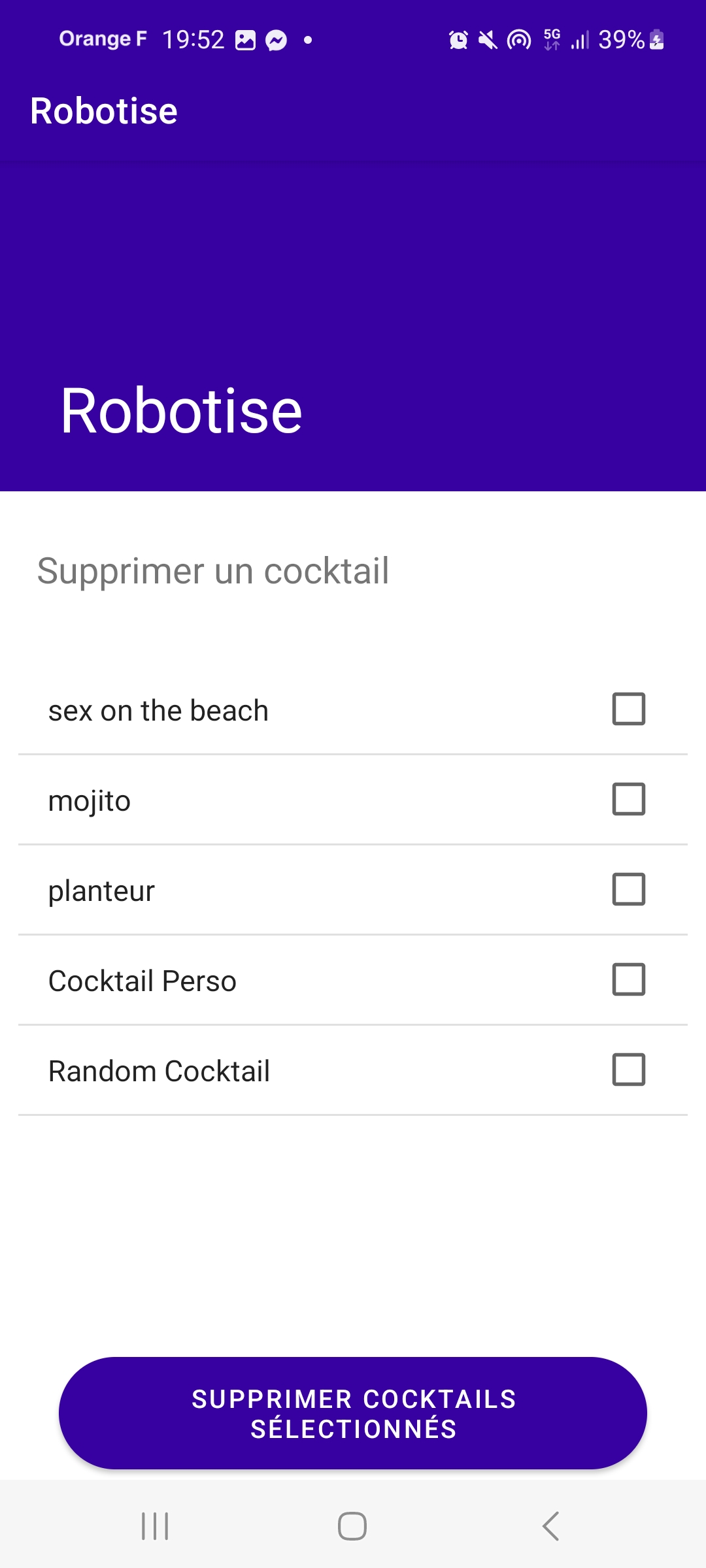 Pour ajouter ou supprimer un cocktail, le principe est le même. Pour ajouter un cocktail, on ne peut le faire qu’à partir de la liste des ingrédients déjà présents dans la base de données.
Pour ajouter ou supprimer un cocktail, le principe est le même. Pour ajouter un cocktail, on ne peut le faire qu’à partir de la liste des ingrédients déjà présents dans la base de données.
Si l’on souhaite ajouter un cocktail contenant un ingrédient qui n’est pas encore présent dans la base de données, il faut d’abord ajouter cet ingrédient en utilisant les options d’ajout d’ingrédients décrites précédemment.

Lien vers les sources applications :
[1]:https://github.com/android/connectivity-samples/tree/main/BluetoothLeGatt
[2]:https://developer.android.com/reference/android/bluetooth/BluetoothGatt.html
Structure
Robotise
├── app
│ ├── libs
│ ├── src
│ │ ├── androidTest
│ │ │ └── java
│ │ │ └── com/example/robotise
│ │ └── main
│ │ ├── java
│ │ │ └── com/example/robotise
│ │ │ ├── ble
│ │ │ ├── bluetooth
│ │ │ ├── control
│ │ │ ├── list
│ │ │ └── model
│ │ │ └── morpion
│ │ └── res
│ │ ├── drawable
│ │ ├── layout
│ │ ├── menu
│ │ ├── mipmap
│ │ └── values
│ └── build.gradle
├── build.gradle
└── settings.gradle
-
Communication BLE sur Raspberry Pi
Sur le Raspberry Pi, la bibliothèque « ble » contient toutes les classes utiles à l’implémentation du serveur GATT sur Raspberry Pi. Le fichier main.py doit être lancé sur le Raspberry Pi, il crée un serveur GATT qui va pouvoir communiquer avec l’application.
Organisation
Cette bibliothèque contient 3 fichiers :
- advertisement.py : Contient les classes nécessaires à l’émission des différents UUIDs après la création du serveur.
- gatt_server.py : Contient les classes nécessaires à la création du serveur et l’initialisation de ses différents paramètres.
- main.py : Initialise le serveur BLE en utilisant les classes réalisées précédemment.
Fonctionnement
Les concepts abordés dans la partie suivante sont expliqués ici : https://www.bluetooth.com/bluetooth-resources/intro-to-bluetooth-low-energy/
Les fichiers advertisement.py et gatt_server.py ne sont pas de nous et à ce titre, ne feront pas l’objet d’une documentation (Crédit : https://github.com/bluez/bluez).
Le fichier main.py utilise advertisement.py et gatt_server.py pour créer le serveur BLE.
On dispose de deux classes :
- TxCharacteristic qui gère la communication dans le sens Raspberry PI -> Téléphone
- RxCharacteristic qui gère la communication dans le sens Téléphone -> Raspberry PI
Ensuite, on redéfinit des classes pour chaque opération que l’on veut réaliser (mise à jour de base de données, commande, etc), chacune est identifiée par un UUID référencé en début de fichier.
Tous les UUID ne sont pas utilisés, mais ils permettent de couvrir l’intégralité des cas imaginés.
-
Manipulation de la base de données
Sur le raspberry, la bibliothèque « sql » contient toutes les classes et fonctions utiles pour l’intéraction entre le base de données et le fichier python.
Fonctionnement
Voici une description du rôle de chaque fonction de la bibliothèque :
- mysql_get_cocktail_list() : Permet de récupérer toutes les colonnes de la table cocktail.
- mysql_get_ingredient_list() : Permet de récupérer toutes les colonnes de la table ingredient.
- mysql_get_quantite_machine() : Permet de récupérer toutes les colonnes de la table machine.
- mysql_get_all_cocktail_composition_without_bec(id_cocktail) : Prend en entrée l’identifiant du cocktail, réalise une jointure entre les tables composition, cocktail et ingredient et retourne id_cocktail, nom_cocktail, id_ingredient, nom_ingredient et quantite.
- mysql_get_all_cocktail_composition_with_bec(id_cocktail) : Prend en entrée l’identifiant du cocktail, réalise une jointure entre les tables composition, cocktail et ingredient et retourne id_cocktail, nom_cocktail, id_ingredient, nom_ingredient, quantite et id_bec.
- mysql_get_bec_from_ingredient(id_ingredient) : Prend en entrée l’identifiant d’un ingredient, retourne le numéro de bec associé.
- mysql_add_ingredient(nom_ingredient) : Prend en entrée le nom d’un ingrédient, puis l’ajoute dans la base de donnée. L’identifiant de l’ingrédient est automatique et le numéro de bec est initialisé à NULL.
- mysql_maj_machine(maj) : Prend en entrée une liste de tuples au format : ‘machine.id_bec’,’ingredient.id_ingredient’,’machine.quantite’, dans la table ingredient passe toute la colonne id_bec à NULL (pour ne pas avoir de doublon), pour chaque identifiant de bec dans la table machine, rajoute la quantite passée en argument et enfin, dans la table ingrédient ajoute le numéro de bec correspondant à l’ingrédient.
- mysql_get_composition_for_machine(commande) : Prend en entrée une liste de tuples au format : ‘id_cocktail’,’id_ingredient’,’quantite’ réalise une itération dans la liste pour retourner une liste de tuples au format ‘id_bec’,’quantite’ ou id_bec représente l’identifiant du bec lié à l’identifiant de l’ingredient passé en argument. Si un ingrédient ne dispose pas de numéro de bec, il n’est pas présent dans la machine donc on sort de la boucle et on retourne None.
- formalize_data_list(function) : Prend en entrée une fonction (l’une des fonctions ci-dessus) et convertis la sortie soit un tuple ou une liste de tuples en chaine textuel (x,y,z/a,b,c) afin de permettre l’envoie en Bluetooth.
- unformalize_data_list(initial_data) : Inverse de la fonction précédente, prend en entrée un string au format x,y,z/a,b,c et reconvertis en tuple ou liste de tuple
-
Interaction Python / plaque PCB
Concernant le code, tous les détails se trouvent dans le README de la partie machine. Voici quelques informations :
Le code permet de faire l’interface entre la commande utilisateur (bec, quantité) avec les différents becs de la machine et les composants utilisés.
Dans la machine, les becs 1 et 2 utilisent la pompe 1, tandis que le bec 3 utilise la pompe 2. Chaque bec a sa propre électrovanne pour contrôler le liquide voulu, et un débitmètre se trouve en sortie et renvoie un signal lorsqu’il détecte un liquide le traversant.
Pour faire l’interfaçage avec le Raspberry Pi, on trouve la fonction setupGPIO qui configure les entrées-sorties et les PWM pour les pompes.
La fonction stopLine arrête tous les composants, entre chaque ingrédient de la commande, à la fin de la commande, ou bien en phase de test à la fin du programme.
La fonction startLine gère la majeure partie du programme. On peut s’en servir pour amorcer le robot et ses pompes, ou bien en fonctionnement normal pour gérer le pompage d’un ingrédient. À l’intérieur, on ajoute l’évènement de callback du débitmètre pour contrôler la quantité de liquide pompée, et on lance startPompage pour chaque ingrédient, fonction simple qui démarre les pompes avec une PWM.
Le fichier main.py peut être lancé pour les phases de test.
IV – Résultats, difficultées rencontrées et perspectives
Parcourons les différentes disciplines du projet afin de balayer l’ensemble des résultats que nous proposons en fin de projet, les difficultés que nous avons rencontrées et ce que nous imaginons pour le futur de ce projet.
-
Difficultés rencontrées
Concernant la partie machine, le design de la carte mère et le code Python contrôlant les composants n’ont pas posé de problème particulier, grâce aux nombreux tests intermédiaires effectués tout au long du projet. Cependant, un problème conséquent est apparu en milieu de projet concernant l’étanchéité du circuit hydraulique. Certaines pièces imprimées en 3D, comme les raccords et les multiplexeurs, peuvent facilement engendrer des fuites ou laisser passer des bulles d’air, ce qui désamorce les pompes et rend le circuit d’eau inutilisable. L’idéal aurait été d’acheter également en amont ces différents raccords pour éviter ces problèmes. Nous avons surmonté ce problème grâce à l’utilisation de téflon de plomberie.
Concernant la partie application, le choix du protocole de communication a été la principale difficulté. En effet, la communication BLE est complexe de base, et nous avons dû l’implémenter en différents langages : Python et Java. De plus, ce protocole de communication est assez instable. Par exemple, l’application ne reconnaît pas toujours le Raspberry Pi en tant qu’appareil BLE disponible. Il faut donc redémarrer le service Bluetooth sur Raspberry Pi.
-
Résultats
Tous les composants ont pu être intégrés à la machine, et l’alimentation 5V / 12V se branche directement au secteur, ce qui permet d’alimenter le Raspberry Pi et la carte de puissance. La machine finale comprend 3 réservoirs de liquide que l’on peut remplir via le haut des bouteilles.
Concernant la partie application :
L’application fonctionne correctement, et l’utilisateur peut communiquer avec la base de données comme il le souhaite et commander le cocktail de son choix. Pour la démonstration, nous avons choisi de mettre trois colorants alimentaires RJB (rouge, jaune et bleu) dans les réservoirs afin de pouvoir réaliser toutes les couleurs possibles (censées symboliser les cocktails en utilisation normale). Les résultats étaient très probants, et la machine a pu fonctionner toute la matinée du forum PROCOM sans souci notable, autant du côté machine que du côté application.
État final de la machine : Rendu 3D / Châssis final




Nous sommes très satisfaits du résultat, après de nombreuses difficultés. Le travail en équipe était très efficace et nos liens se sont renforcés. Nous encourageons les lecteurs de cet article à proposer des projets de ce type à l’IMT, source d’interdisciplinarité et de liberté dans les choix du projet.
-
Perspectives
Les perspectives d’améliorations sont les suivantes :
- réaliser une ligne pour le rinçage et l’ajouter au système
- rajouter d’autres lignes pour avoir une multitude de choix
- faire un châssis plus solide avec des matériaux plus adaptés (résistant à l’eau)
- mettre une interface graphique intégrée au robot
V – Annexes
Lien gitlab : https://gitlab.imt-atlantique.fr/procom2022-robotise/
Publicité diffusée lors du forum Projet :
