
22/12/2023
Auteurs:
Anna Terra GOMES GUERRA, Mathieu BOURGES, Dely Catalina ARDILA MEDINA
TABLE DES MATIÈRES
- Introduction
- Hardware
- Software
- Serveur TTN
- Serveur base de données
- Monter un serveur WEB
- Setup de la raspberry
- Apache2
- Installation de php
- Installation du serveur de base de donnée
- phpMyAdmin, notre interface pour configurer la base de données
- Mise en place des utilisateurs
- Installation de la base de donnée
- Installation du site web
- Création de l’API MQTT de TTN
- Setup python sur la raspberry
- Script pour la récupération des données en MQTT sur la raspberry
- Page Web 25
- Perspectives et conclusiones
I. Introduction
A. Objectif du projet (et les domaines/technologies qu’il couvre)
Conception d’un modèle novateur de système de collecte des déchets flottants dans les rivières, conçu pour atténuer la pollution de l’eau avant d’atteindre l’océan. Ce système intègre des bouées rotatives élégantes qui dirigent avec habileté les déchets flottants vers un conteneur intelligent connecté via la technologie LoRa. Cette solution contribue non seulement à la préservation de l’environnement, mais recueille également des données précieuses dans une base de données, offrant un accès aisé pour les futures recherches et observations. De plus, elle propose une expérience interactive via une page web conviviale, permettant aux utilisateurs de visualiser de manière intuitive l’état du système grâce aux lectures précises des capteurs, soulignant ainsi notre engagement envers un avenir plus propre et durable.

B. Spécifications du projet
a. Diagramme de cas d’utilisation
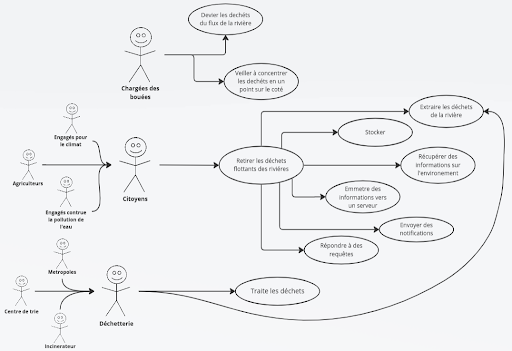
Ce schéma met en lumière les caractéristiques mises en œuvre par le système et les divers acteurs associés à ces actions. Les acteurs clés qui interagissent comprennent les responsables du système de bouées, les citoyens et les responsables des déchetteries. Les responsables des bouées initient les interactions en évaluant l’adéquation environnementale, les citoyens jouent un rôle prépondérant dans le processus d’entretien du système et dans la collecte manuelle des déchets, tandis que les responsables des déchetteries se chargent du traitement des déchets au-delà des responsabilités du citoyen ordinaire. Cette collaboration dynamique entre ces acteurs crée un écosystème efficace pour la préservation de notre environnement.
C. Diagramme de blocs d’architecture
Ce schéma offre un aperçu captivant de la conception du système et des interconnexions qui le caractérisent. Il met en lumière les flux de données entre les capteurs, la carte Arduino avec son module Lora Groove Wio E5, les serveurs dédiés au traitement et au stockage des données, ainsi que le site Web permettant une visualisation aisée. Il illustre également le cheminement des déchets flottants, depuis les bouées rotatives jusqu’au conteneur à ordures interconnecté.
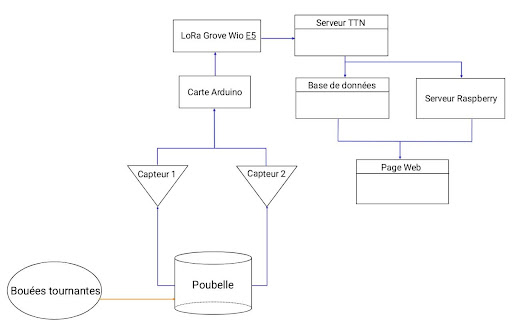
En résumé, ce schéma offre une vision claire des interactions entre les éléments clés du système, mettant en avant les flux de données et de déchets qui facilitent le fonctionnement harmonieux du système de collecte des déchets flottants RiverCleaner.
II. Hardware
A. Conception 3D
Voici une représentation 3D immersive des 3 bouées tournantes, vue sous différentes perspectives pour une appréciation maximale.
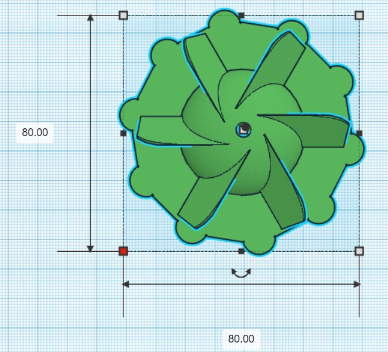
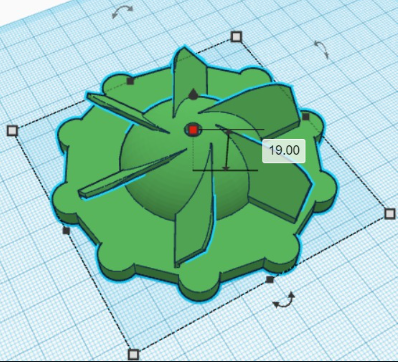

Pour la conception de la bouée rotative, l’inspiration a été puisée d’un projet existant sur https://rivercleaning.com. Le modèle a été adapté aux exigences spécifiques du système, en tenant compte des caractéristiques uniques de notre environnement d’essai. Ainsi, la décision a été prise d’équiper la bouée de pales de ventilateur pour optimiser sa rotation selon le flux d’eau des rivières, avec un diamètre réfléchi à 80 mm pour s’intégrer harmonieusement à l’environnement environnant.
De manière similaire, trois de ces bouées ont été déployées pour assurer un acheminement continu des déchets flottants vers le panier à ordures. Ces bouées sont fixées au fond grâce à un axe adaptable, offrant une flexibilité d’implémentation qui permet non seulement le passage aisé de petits bateaux si nécessaire, mais aussi le respect de la vie marine des rivières. De plus, leur adaptabilité au niveau de l’eau, sujet à des variations fréquentes au fil du temps, renforce leur efficacité dans des conditions changeantes. Cette approche ingénieuse garantit une solution robuste et adaptable pour la collecte efficace des déchets flottants.
B. Conception dans la découpeuse laser
Voici la conception innovante des faces du panier à ordures, pensée avec des filtres et des tiges pour garantir la rotation fluide des bouées au sein de notre environnement de test :
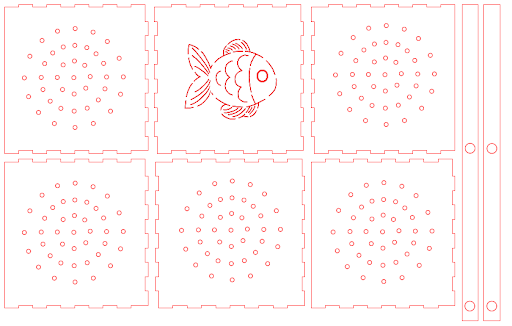
Initialement conçue comme une poubelle parfaite de 90x90x90 mm, la conception du panier à ordures s’est réduite au fil du processus à la mise en œuvre de seulement 4 faces, dont l’une arbore un filtre en forme de poisson pour injecter de la personnalité dans le projet et renforcer l’image de la marque. Deux barres de 14 x 274,5 mm ont été ingénieusement intégrées en tant que poutres, maintenant les bouées rotatives pour optimiser l’utilisation du matériau et assurer une adaptabilité accrue à l’environnement. Cette approche créative ajoute non seulement du caractère au projet, mais renforce également l’esthétique globale et l’attrait visuel de la marque.
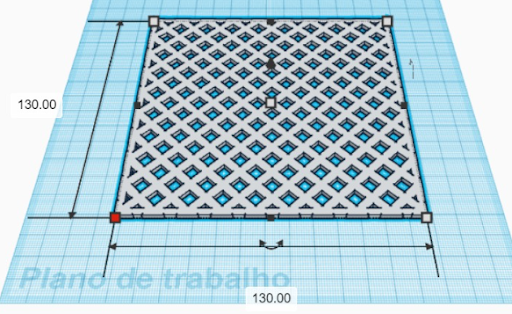
En outre, à la suite de tests visant à affiner le système de collecte des déchets, une décision innovante a été prise de remplacer l’arrière du conteneur par une structure en maille imprimée en 3D avec des trous de 6 mm x 6 mm et un espacement de 2 mm entre eux. Cette modification est conçue pour favoriser une circulation optimale de l’eau tout en améliorant la rétention des déchets dans le système.

C. Environnement de test
a. Liste matériel pour configuration
- 1 grand conteneur
- 1 Pompe à eau
- 1 mur de séparation
- Supports pour panier à ordures
- Fil de fer
- Ruban isolant
- Eau



Pour la mise en œuvre de l’environnement de test, nous avons choisi un grand récipient d’eau, dans lequel une pompe à eau a été stratégiquement installée pour créer un courant simulé, imitant l’écoulement d’une rivière. En outre, un mur de séparation a été placé au centre du conteneur afin d’assurer une circulation uniforme autour de celui-ci. Cette disposition intelligente empêche tout croisement inattendu des courants, évitant ainsi tout comportement indésirable des bouées, comme des virages inattendus ou des interruptions du mouvement cinétique. Cette configuration permet une simulation réaliste et contrôlée, créant un environnement d’essai idéal pour évaluer les performances du système. Pour fixer les bouées au modèle, nous avons choisi d’utiliser des fils moulables, en les faisant passer verticalement à travers les bouées, et un fil horizontalement pour assurer la stabilité, comme l’illustrent les images. Étant donné la proximité de ces fils avec l’eau, nous avons appliqué du ruban isolant à titre préventif afin d’éviter tout problème futur.
D. Électronique (RiverCleaner)
a. Liste du matériel
- 1 Module Lora Grove Wio E5
- 1 Arduino Leonardo
- 1 Capteur de niveau d’eau
- 1 Détecteur de distance à ultrason.
- 1 Arduino Grove Base Shield
Chacun de ces modules occupe un rôle clef dans le projet :
- Le capteur à ultrason, va détecter quand la poubelle est pleine
- Le capteur de niveau d’eau, va nous donner des informations sur le niveau de la rivière (si il est supérieur ou inférieur à la normale)
- Le buzzer, va fournir une information sonore sur l’état du système
- Le LoRa-E5, va nous permettre d’envoyer les données en LoRa sur un serveur.
Vous trouverez ci-dessous le schémas de montage du système :
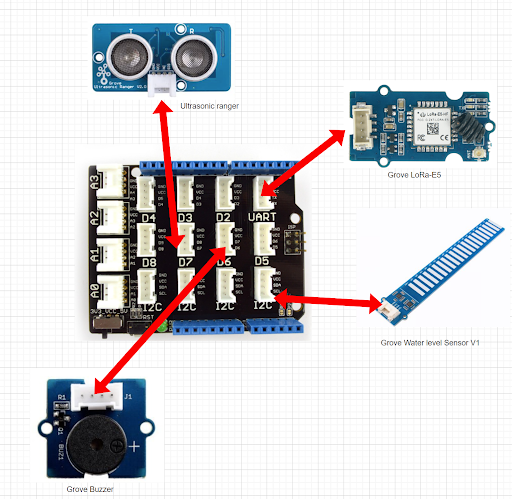
Sur le port UART, nous retrouvon le module LoRa-E5
Sur le port D6, se trouve le Buzzer
Sur le port D7, le détecteur à ultrason (Ultrasonic Ranger)
Sur le port I2C Droit, se trouve le capteur de niveau d’eau
b. Parlons bien, parlons code
Notre projet est fait sur arduino, nous avons donc développé notre code sur cette plateforme. L’ensemble du code du projet se trouve sur un gitlab hébergé sur les serveurs de IMT Atlantique. Le gitlab est disponible en suivant ce lien dans la section arduino : https://gitlab.imt-atlantique.fr/m21bourg/rivercleaner
Plusieurs remarques sont à faire à cette étape :
- Assurez-vous d’avoir une Arduino Léonardo. LE CODE NE FONCTIONNE PAS POUR D’AUTRE TYPES DE CARTES !!!!
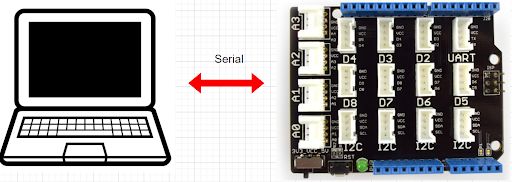
- Assurez-vous d’avoir une liaison série entre le PC et la carte. Le programme ne se lancera pas tant qu’il n’aura pas réussi à établir une liaison série. (Vous pouvez shunter cette sécurité en commentant la ligne 55 “while (!USB_Serial);” ).
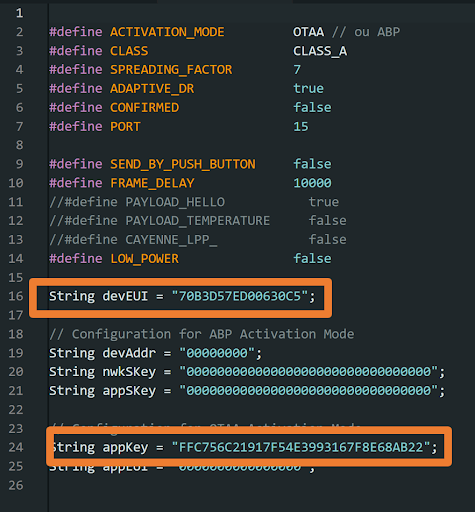
- Dans le fichier config_application.h Changez le DevEUI (mettez celui qui vous est fourni par TTN)
- Dans le fichier config_application.h Changez l’AppKey (mettez aussi celui qui vous est fourni par TTN)
III. Software
A. Serveur TTN
Pour établir la connexion avec le serveur TTN, il est impératif de créer un « End device », dans notre cas, le module Lora Grove Wio E5, chargé de communiquer les données lues par la carte Arduino avec The Things Network.
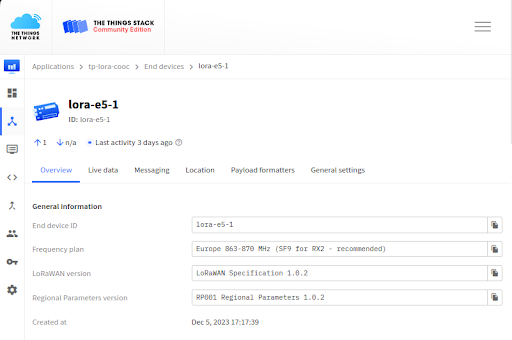
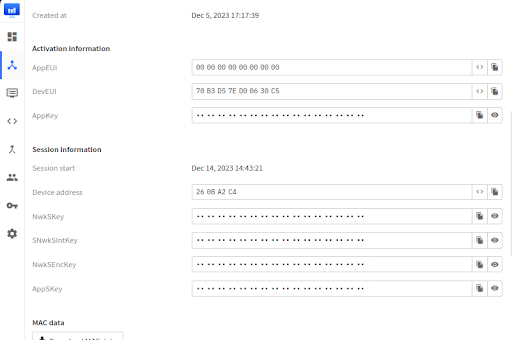
Cette démarche permet d’obtenir les informations d’identification essentielles pour une connexion réussie et une lecture correcte des données récupérées. Ultérieurement, ces données servent également à établir des liens entre les bases de données et les serveurs qui interagissent de manière transparente avec l’utilisateur. Ce processus garantit une intégration harmonieuse et efficace des données dans l’écosystème du projet.
B. Serveur base de données
Dans cette étape cruciale, les données capturées sont méticuleusement archivées dans une base de données, offrant ainsi la possibilité de les consulter en fonction de divers paramètres tels que la date, l’heure, la quantité de déchets, le niveau d’eau, et bien d’autres. Cette approche réfléchie permet une analyse approfondie et une visualisation personnalisée des informations, fournissant ainsi une compréhension holistique des tendances et des schémas liés à la gestion des déchets flottants.
Pour le serveur de base de données, nous avons fait le choix d’utiliser un serveur mySQL. Ce choix présente plusieurs avantages :
- Facilité de mise en place
- Bonne gestion d’une grosse quantité de donnée
- Facilité de lien avec différents autres services
La base de donnée est construit sur le schémas suivant :
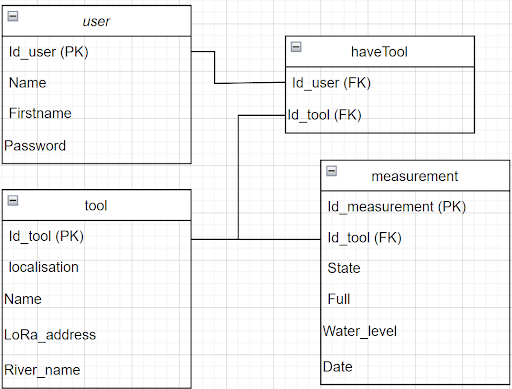
user désigne les utilisateurs. Un utilisateur est représenté par :
- Un ID (numéro d’utilisateur)
- Name (un nom)
- Firstname, un prénom
- Password (un mot de passe)
tool désigne l’outil riverCleaner. Il est représenté par :
- Un ID
- Location, la localisation de la station
- LoRa address : L’adresse LoRa pour contacter l’outil
- River name : le nom de la rivière ou l’outil est installé
Etant donné qu’un utilisateur peut avoir un ou plusieurs outils nous avons une table de liaison “haveTool” qui fait le lien entre user et tool.
Enfin, vu qu’un outils peut faire des mesures, nous avons une table measurement qui contient l’ensemble des mesures des outils, une mesure est décrite par :
- Un ID
- L’identifiant de l’outil qui à fait la mesure
- State : désigne l’état du système
- Full : un boolean qui indique si la poubelle est pleine ou non
- Water_level : donne une information sur le niveau d’eau de la rivière
- Date : horodatage de la mesure (créé automatiquement par la base de donnée).
C. Monter un serveur WEB
Matériel :
- Raspberry PI 4 B+
- Carte micro SD (4 Go minimum requis)
- Moniteur, clavier, souri, connexion internet
a. Setup de la raspberry
Dans un premier temps, nous allons préparer la raspberry. Pour cela nous allons avoir besoin d’un OS. Dans un premier temps, allez chercher une Image sur le site de raspberry (https://www.raspberrypi.com/software/operating-systems/ ). Pour vous faciliter la tâche, je vous recommande une image Raspberry Pi OS with desktop and recommended software. Bien qu’elle soit plus grosse, elle dispose de quelques outils pré-installés, qui vous aideront lors du débugage.
Flashez la carte SD avec l’image de Raspberry PI OS avec l’outil de votre choix (je vous recommande balena Eatcher https://etcher.balena.io/ ).
Une fois la carte SD flashée, insérée la dans la raspberry, et mettez le système sous tension. Au bout de quelques minutes, vous devriez arriver sur l’outil d’aide à l’installation.
Si cela ne fonctionne pas :
- Vérifiez que le moniteur est sous tension, et qu’il a la bonne source
- Vérifiez la présence de fichier sur la carte SD (vous avez peut-être flasher autre chose, comme une clef USB)
- Vérifiez que vous avez bien flasher un image de raspberry pi OS (non de Raspberry Pi OS for VM)
Suivez le guide d’installation, et faites les éventuelles mise à jour. Une fois la raspberry complètement installée, redémarrez la.
b. Apache2
Nous allons maintenant passer à la configuration de la raspberry afin de la transformer en serveur web.
Tapez ‘sudo /etc/init.d/apache2 restart’. Si vous avez un message de redémarrage, vous pouvez passer à l’étape de l’installation de php.
![]()
Sinon, nous allons installer manuellement le serveur apache.
Tapez ‘sudo apt install apache2’ Cette commande va installer un serveur apache (eq serveur web html) sur la raspberry.
Afin de vérifier si le serveur est bien installé, ouvrez un navigateur, et tapez dans la barre de recherche ‘localhost’ ou ‘127.0.0.1’. Vous devriez arriver sur une page comme celle-ci :

Si ce n’est pas le cas :
- Faites une MAJ sur la carte (‘sudo apt-get update’ puis ‘sudo apt-get upgrade’, puis reboot)
- Tentez de réinstaller le serveur (‘sudo apt-get install apache2’)
- Essayez la commande ‘/etc/init.d/apache2 restart’
- demandez à chatGPT de l’aide
c. Installation de php
Nous allons maintenant passer à l’installation de php.
Dans votre terminal, tapez la commande ‘sudo nano /var/www/html/example.php’.
Une fenêtre devrait s’ouvrir. Entrez les lignes de code suivantes :
<!DOCTYPE html>
<html>
<?php
print(“<h1>HELLO WORLD !!!!</h1>”);
?>
</html>
Dans votre navigateur, dans la barre d’adresse, tapez ‘localhost/example.php’. Si vous observez un HELLO WORLD !!!! marqué en très gros. Vous pouvez passer à la partie installation du serveur sql.
Si vous avez une erreur, vous avez sans doute mal recopié le code donné ci-dessus. Vérifiez bien la présence de “;” à la fin de la ligne de code.
Si vous avez seulement une page balance, cela signifie que php n’est pas installé sur la raspberry.
Nous allons installer php à la main. Pour cela, tapez la commande ‘sudo apt-get install php’. Cette commande devrait installer automatiquement la dernière version de php. Confirmez cela en regardant la version de php (‘php -v’). Réessayez de charger la page “localhost/example.php”.
Cela ne fonctionne toujours pas :
- Vérifiez l’URL
- Redémarrez le serveur apache “/etc/init.d/apache2 restart”
- Redémarrez la raspberry
- Renseignez vous sur internet
d. Installation du serveur de base de donnée
Les étapes qui vont suivre sont un peu plus complexes. Je vous recommande de suivre les documentations en ligne.
Nous allons passer à l’installation du serveur de base de données mysql. Pour cela tapez la commande ‘sudo apt-get install mysql-server’. Cette commande va permettre d’installer un serveur mysql sur la raspberry. Bien que dans une certaine mesure c’est mieux, je vous déconseille de faire la sécure installation de mysql, cela peut bloquer votre base de donnée, et vous serez obligé de flasher à nouveau la carte SD.
Afin de vérifier sa bonne installation, tapez la commande ‘sudo mysql’.
Si vous avez ce message (à quelques différences près), félicitation, vous avez un serveur SQL, vous pouvez passer à l’installation de phpmyadmin.
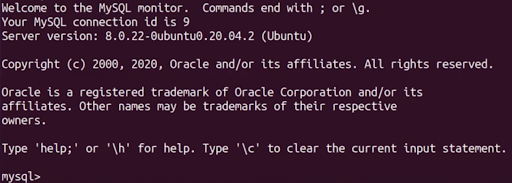
Afin de sortir du terminal mysql tapez la commande exit.
Si la commande ne fonctionne pas, regardez la documentation en ligne.
e. phpMyAdmin, notre interface pour configurer la base de données
Une fois votre base de données installée, nous allons procéder à l’installation de l’outil qui va la gérer : phpMyAdmin.
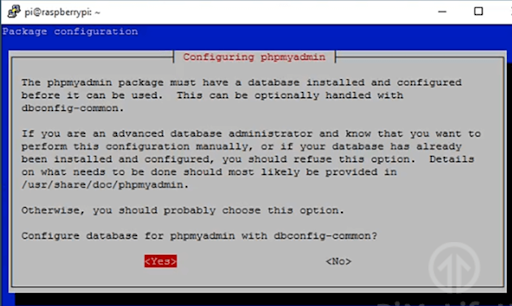
Pour cela, tapez la commande ‘sudo apt-get install phpmyadmin’.
Dans un premier temps phpmyadmin vous demandera des accès à la base de donnée faites Entrée pour accepter
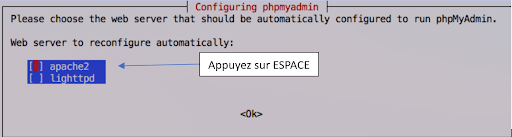
Ensuite, il vous demandera quel serveur web nous souhaitons reconfigurer. Faites ESPACE afin de sélectionner apache2, et appuyer sur Entrée
Normalement c’est tout bon. Allez sur la page de connexion de phpmyadmin en tapant dans votre navigateur ‘localhost/phpmyadmin/’
Si vous avez une page qui ressemble à cela, vous avez réussi à setup phpmyadmin :
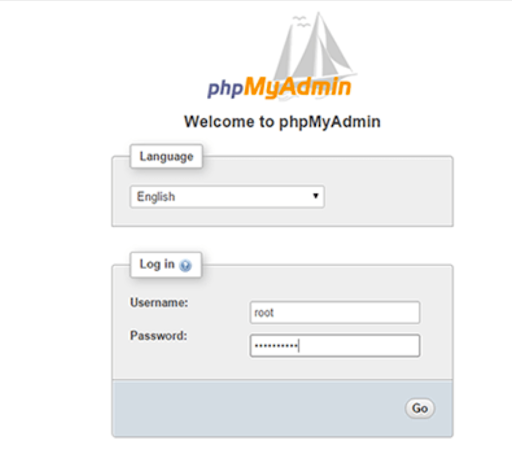
Si cela ne fonctionne pas :
- Redémarrez apache ‘/etc/init.d/apache2 restart’
- Redémarrez la raspberry
- Cherchez dans la documentation en ligne (https://pimylifeup.com/raspberry-pi-phpmyadmin/)
f. Mise en place des utilisateurs
Dans cette étape, nous allons mettre en place les utilisateurs de la base de données.
Tapez ‘sudo mysql’ Vous devriez ouvrir un terminal mysql.
Ensuite tapez la commande :
CREATE USER ‘[username]’@’localhost’ IDENTIFIED BY ‘[password]’;
Remplacez [username] par un nom d’utilisateur ex : ‘user’@’localhost’
Remplacez [password] par le mot de passe de votre choix ex : ‘password’
N’oubliez pas le “;” à la fin de la requête.
Ensuite, nous allons attribuer des droits à cet utilisateur. Pour cela tapez la commande :
GRANT ALL PRIVILEGES ON *.* TO ‘[username]’@’localhost’ IDENTIFIED BY ‘[password]’ WITH GRANT OPTION;
Remplacez [username] par un nom d’utilisateur ex : ‘user’@’localhost’
Remplacez [password] par le mot de passe de votre choix ex : ‘password’
N’oubliez pas le “;” à la fin de la requête.
Retournez sur la page de connexion de phpmyadmin et entrez le couple login mot de passe que vous venez de créer. (utilisez [username] pour le login, pas besoin du @’localhost’)
Si vous êtes connecté, félicitation ! Vous avez phpmyadmin à votre disposition.
Sinon :
- Vérifiez que vous avez bien le bon couple login mot de passe
- Redémarrez apache2 ‘sudo /etc/init.d/apache2 restart’
- Redémarrez la raspberry
- Cherchez de l’aide en ligne
g. Installation de la base de donnée
Nous allons maintenant passer à l’installation de la base de données.
Dans un terminal tapez ‘sudo mysql’
Puis : CREATE DATABASE riverCleaner;
Cette commande va créer une base de donnée dans le serveur mysql.
Retournez dans phpmyadmin et retrouvez la base de donnée rivercleaner, cliquez dessus (cela permet de la sélectionner) et importez la base de donnée river cleaner disponible sur le gitlab : https://gitlab.imt-atlantique.fr/m21bourg/rivercleaner
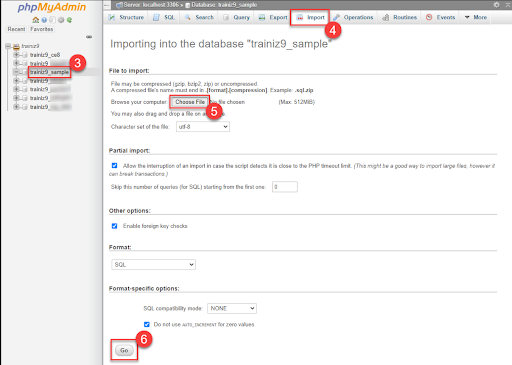
Maintenant, vous avez une base de données pour votre projet !
h. Installation du site web
Mettez sur une clef USB le code du site web disponible sur le gitlab https://gitlab.imt-atlantique.fr/m21bourg/rivercleaner
Sur la raspberry, déplacez le fichier ‘WEB’ sur le bureau
Dans un terminal taper la commande suivante :
sudo cp -R ./Desktop/WEB/ /var/www/html/
Cette commande à pour effet de copier le dossier WEB et le coller dans le dossier /var/www/html
Dans un navigateur recherchez l’adresse ‘localhost/WEB/’. Vous devriez arriver sur la page d’accueil de riverCleaner.
Notre objectif est maintenant de réaliser le montage suivant :
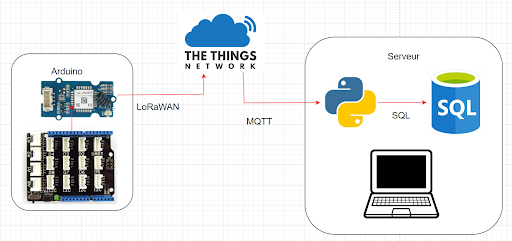
Pour cela, nous allons avoir besoin de créer un lien entre la base de données et le serveur SQL. Cela va se faire en deux temps. Dans un premier temps nous allons faire en sorte que le serveur nous envoie les informations, puis nous allons les récupérer avec un code python
i. Création de l’API MQTT de TTN
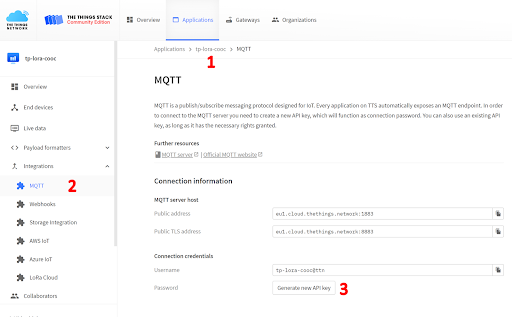
Nous allons maintenant créer l’API MQTT qui servira à récupérer les informations émises en LoRa par la carte arduino.
Pour cela connectez vous à TTN. Dans application -> tp-lora-cooc -> MQTT.
Cliquez sur “generate new API key”. Ceci va générer une clef API pour que l’on puisse se connecter en MQTT à l’ensemble du service “tp-lora-cooc”. Notez bien aussi le username “tp-lora-cooc@ttn”, celui-ci nous sera très utile pour la suite.
j. Setup python sur la raspberry
Pour commencer, installons pythons sur la raspberry :
sudo apt-get install python3-full
C’est une version plus complète de python (qui intègre un peu plus d’outils dès le départ).
Ensuite nous avons besoin d’installer différentes librairies :
- paho-mqtt -> permet de recevoir des flux en MQTT
- mysql-connector -> qui permet de s’interfacer facilement avec la base de donnée
Vous pouvez les installer facilement avec pip :
pip install paho-mqtt
pip install mysql-connector
Si cela ne fonctionne pas :
- Redémarrez la raspberry (surtout si vous venez tout juste d’installer python)
- Renseignez vous sur les problème de virtual environnement (les .venv)
- Téléchargez pip (le script get-pip.py disponible sur le site officiel de pip fonctionne bien)
- Regardez la documentation en ligne
k. Script pour la récupération des données en MQTT sur la raspberry
Nous allons pouvoir installer le script qui permet de faire la liaison entre le serveur TTN et la base de données SQL. Dans un premier temps récupérez le script python disponible sur le gitlab : https://gitlab.imt-atlantique.fr/m21bourg/rivercleaner.
Mettez les valeurs adéquat pour lier votre raspberry au serveur TTN.
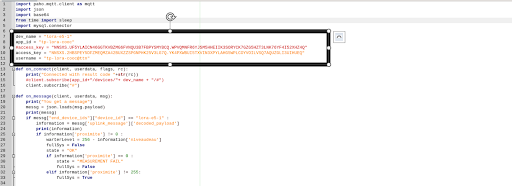
Et à la fin du document remplissez les champs avec vos informations de connexion avec la base de données :
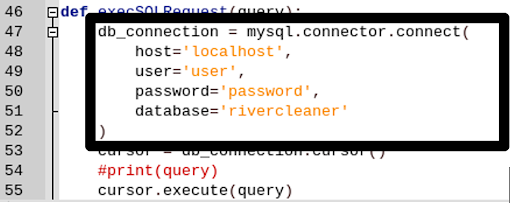
Une fois ceci fait, vous pouvez exécuter le script python avec la commande :
python3 [VotreScript].py
ou [VotreScript] est le nom de votre script.
Si vous recevez des informations sur votre serveur, celles-ci seront automatiquement transmises dans le terminal, et si elles sont compatibles, elles iront dans la base de données.
D. Page Web
a. Functionnalités
La page web permet à l’utilisateur d’avoir une vue sur son système. Combien de polluants, il a retiré de la rivière, l’état du système, …
La page web est hébergée sur un serveur apache. Elle est liée à la base de données. La page web dispose aussi d’une API sur laquelle les scientifiques peuvent se connecter afin de recevoir des mesures des différents outils.
Bien que nous n’ayons pas eu le temps de mettre en place l’API, nous avons pu commencer à travailler sur le site web. Le site web à un front-end en html, un backend en php et bootstrap 3 pour toute la partie “CSS”.
Le site est composé de plusieurs pages :
- Page d’accueil
- Page de relevé des mesures
- Page de création de compte
- Page de login
La page d’accueil regroupe différentes informations sur ce qu’est le projet riverCleaner, ce qu’il fait, à quoi il sert …
La page de relevé des mesures, se contente d’afficher les mesures présentes dans la base de données. A terme, le but sera d’afficher les mesures relatives à un utilisateur, avec des options de filtrage (filtrer par appareil, filtrer par date, …)
Page de création de compte. Cette page sert à se créer un compte riverCleaner. Elle prend comme entrée Nom, Prénom et mot de passe. Il est possible de faire de l’injection de code dans la page.
Page de login, cette page sert juste à se logger sur le site. Pour l’instant elle affiche juste un message pour indiquer que l’authentification à réussi, mais à terme, il faudra mettre les mécanismes de session PHP, pour garder l’authentification.
function.php est un fichier central dans ce site. Il permet de centraliser des fonctions php communes au site web. Par exemple, il centralise les fonctions relatives au header, footer, navbar, connexion à la base de données, imports bootstrap … Si vous souhaitez récupérer le site, vous devrez passer un peu de temps pour comprendre ce fichier.
IV. Perspectives et conclusiones
A. Perspectives
Les perspectives d’avenir de ce projet sont prometteuses. La technologie utilisée pour collecter les déchets flottants dans les rivières pourrait être adaptée à d’autres applications, notamment dans les grandes rivières. En outre, l’ajout de fonctionnalités, telles que la détection de la qualité de l’eau ou la surveillance de la faune, pourrait encore améliorer l’efficacité et l’impact environnemental du système. Enfin, la collaboration avec les autorités locales et les organisations environnementales pourrait permettre d’étendre le système à une plus grande échelle, contribuant ainsi à la préservation de l’environnement à l’échelle mondiale.
B. Conclusions
En conclusion, ce projet de collecte des déchets flottants dans les rivières représente une avancée significative dans la lutte contre la pollution de l’eau. La combinaison de la conception innovante des bouées rotatives, de l’utilisation de capteurs avancés et de la mise en place d’une infrastructure logicielle solide démontre l’efficacité de l’approche multidisciplinaire adoptée. Ce système offre une solution pratique et adaptable pour la collecte efficace des déchets flottants, tout en fournissant des données précieuses pour des recherches futures. Il incarne l’engagement envers un environnement plus propre et durable, tout en ouvrant la voie à de nouvelles possibilités d’amélioration et d’expansion.
