
- Transcripen – Etat de l’art – la problématique de l’interview
- Transcripen – Enquête terrain et données recueillies
- Transcripen – Présentation de la Solution Technique
I/ Contexte
Dans le cadre de notre spécialisation en conception d’objets communicants (TAF CooC) dans notre formation à l’IMT Atlantique, nous avions pour objectif de créer de la valeur par les besoins actuels des entreprises et de l’industrie à l’aide d’objets communicants. En d’autres termes, nous devions réaliser un objet communicant qui réponde à un besoin utilisateur.
Chacun des membres du groupe étant en lien quotidien avec des étudiants et / ou journalistes, nous avons relevé, lors de notre étude terrain, un problème récurrent chez ces deux types d’individus, qui sont confrontés au quotidien à de nombreuses conférences et de nombreux échanges oraux longs, voire fastidieux, et pendant lesquels les personnes en question ne peuvent pas être passives (nécessité de réflexion / compréhension / rebondir sur des questions, …) et prendre l’intégralité de l’oral en note. Nous avons donc décidé de répondre à la problématique suivante pendant ce projet : Comment permettre aux interlocuteurs d’un échange, à l’aide d’un objet connecté, de récupérer l’ensemble des informations véhiculées pendant ce-dernier ?
Après nos études terrains, nous avons imaginé, puis prototypé un stylo / micro connecté qui enregistre un oral lorsque l’utilisateur le décide (à l’aide d’un bouton) et envoie sur l’ordinateur de l’utilisateur, via une application, les audios enregistrés sur le stylo / micro sous format texte (transcrits). Grâce à cet objet, l’utilisateur peut totalement se concentrer pendant l’oral et n’a plus à prendre en note les informations véhiculées. Cette phase de prototypage de ce stylo / micro connecté s’est effectuée à l’aide d’une méthode agile (SCRUM) sur 3 semaines.
Dans cet article, nous allons aborder les détails de la phase de prototypage, afin de vous fournir une explication la plus précise possible de notre prototype (choix du matériel, schéma du montage, l’enregistrement audio, l’interface utilisateur, la transmission du fichier audio de la raspberry à l’interface, l’algorithme de transcription utilisé ainsi les résultats obtenus. Nous aborderons ensuite le résultat obtenu à la fin de ces 3 semaines. Enfin, nous aborderons les perspectives d’évolution de notre projet.
Le code (commenté précisément) pour l’ensemble du prototype est disponible sur le lien Github suivant : https://github.com/camillebrl/Transcripen. Vous trouverez également, dans ce Github, une documentation détaillée de l’ensemble des éléments à installer sur la raspberry, ses configurations, …
II/ Réalisation
A. Choix du matériel détaillés et schéma du montage final
- Le choix de la Raspberry pi vs Arduino : Alors qu’Arduino est un microcontrôleur qui ne peut exécuter que du code compilé, la Raspberry pi fonctionne aussi comme système autonome : si l’Arduino est la plus adaptée pour faire de la gestion de LEDs, de capteurs simples (température, luminosité, distance…), elle ne l’est pas pour la gestion de multimédias tels que les audios notamment. La Raspberry Pi est plus adaptée pour cela. C’est pourquoi nous avons, pour ce projet qui consiste en un enregistrement et une gestion de fichiers audios, opté pour une Raspberry Pi.
- Choix du type de Raspberry Pi : la Raspberry Pi Zero est la plus petite sur le marché aujourd’hui (à l’exception de la Raspberry Pi Pico qui n’a pas d’entrée de carte mémoire intégré, ni de port usb, donc trop pas adaptée à notre projet). Puisque nous avions des contraintes de taille du matériel, afin d’intégrer ce-dernier dans un stylo, nous avons opté pour la carte la plus petite possible, d’où notre choix de la Raspberry Pi Zero. Par ailleurs, il existe 2 types de Raspberry Pi Zero : la W et la simple. Puisque nous avions besoin de Wifi pour notre projet (envoie des fichiers audio à l’application), nous avons opté pour la Raspberry Pi Zero W qui est dotée de la wifi, contrairement à la Raspberry Pi Zero.

- La carte SD: nous avons opté pour une carte SD de 32Gb pour la Raspberry. Effectivement, celle-ci est indispensable à la Raspberry: non seulement elle nous permet de stocker les fichiers audios des enregistrements, mais elle est surtout indispensable à la Raspberry (c’est sur cette-dernière que se trouve l’OS de la Raspberry et l’ensemble de ses configurations)
- Breadboard + fils + bouton poussoir + résistance


- Le microphone utilisé est un Microphone Jack 3,5mm nous y avons intégré un convertisseur analogique numérique a la suite de la prise jack, en effet le microphone produit un signal analogique, hors la carte Raspberry ne traite que les signaux numériques. L’ensemble des composants est détaillé ci dessous :
- Microphone Jack, 3,5 cm. 3 Poles.

- Convertisseur analogique / numérique : 15 cm de câble. Fait la conversion analogique / numérique, intégré une carte son


- Adaptateur câble micro USB / USB mâle:

Entrée: 5V | Sortie: 5 V, câble de 12cm.
Le schéma électronique final de notre objet connecté est présenté ci-dessous:
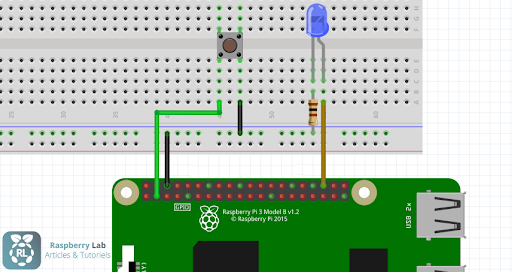
Par ailleurs, nous avons intégré ces composants dans notre objet final, qui prenait la forme d’un stylo. Ci-dessous les images de notre objet final:



Pour le construire, nous avons créé un prototype sur Tinkercad présenté ci-dessous:



B. L’enregistrement audio sur la raspberry
- Le montage du dispositif d’enregistrement
Pour enregistrer des audios à l’aide de notre micro branché en micro-usb à notre Raspberry Pi Zero W, nous avons utilisé 2 bibliothèques python, indispensables à cet égard: Pyaudio et Pydub. PyAudio fournit des liaisons Python pour PortAudio, la bibliothèque de référence qui gère les entrée/sortie usb d’audio sur toutes les plateformes (dont la Raspberry). Quant à Pydub, elle permet de manipuler un fichier audio simplement (ouverture de l’audio, augmentation / diminution du volume de l’audio, segmentation de l’audio, calcul de la durée de l’audio, et toute autre manipulation possible sur un audio. La librairie est en open-source sur https://github.com/jiaaro/pydub). Pour utiliser pydub, il faut installer ffmpeg/avlib.
Pour effectuer l’enregistrement de l’audio, il est important de prendre en compte plusieurs éléments :
- La détection du port sur lequel est branché le micro à la Raspberry : Afin d’identifier ce port, nous avons utilisé la librairie Pyaudio, qui nous a permis, grâce à sa fonction get_device_info_by_index, de trouver le port correspondant au micro.
- Le nombre d’images collectées par seconde par défaut par le micro : Une fois que nous avons identifié l’indice du port correspondant au micro, nous avons pu afficher son “defaultSampleRate”, qui était, dans notre cas, de 48000Hz.
- Le fait que Pyaudio découpe les données en CHUNKS (trames), au lieu d’avoir une quantité continue d’audio, afin de limiter la puissance de traitement requise (RAM), puisque la Raspberry a une RAM assez faible (512M pour notre Raspberry Pi Zero W). Dès lors, nous devions définir le nombre de CHUNKS (trames) dans lesquelles nos signaux seront divisés (il s’agit d’une puissance de 2).
- Une fois que nous avons identifié ces paramètres, nous avons pu instancier un stream (ligne 28 de final_algo.py du Github) qui nous permet ensuite, lorsqu’on appelle la fonction stream.read, d’enregistrer l’audio (ligne 52 du Github).
2. Le montage du dispositif du bouton pour lancer l’enregistrement
L’objectif du bouton est de permettre à l’utilisateur de choisir quand il veut enregistrer et quand il veut d’arrêter d’enregistrer. Un bouton se connecte à une Raspberry Pi à l’aide de ses ports GPIO. Les ports GPIO sont des ports physiques se présentant généralement sous forme de picots métalliques carrés qui permettent de transmettre un signal électrique. Un port GPIO transmet un signal relativement binaire (pas de courant ou du courant). Dans le cas de notre Raspberry Pi Zero W, les ports GPIO travaillent en 3.3V et environ 20 mA. En d’autres termes, les ports GPIO du Raspberry PI permettent d’envoyer du courant (et donc, des informations) à nos composants (les sorties, ici, la Led (que l’on verra ci-dessous)) et récupérer du courant (et des informations) de ceux-ci (les entrées, ici le bouton poussoir). Les ports GPIO de la Raspberry se présentent comme ci contre.

Ils sont numérotés de 1 à 40, en partant du haut à gauche quand vous tenez la Raspberry pi ports GPIO à droite. Cette numérotation de 1 à 40 est le mode de numérotation dit « Board ». Un autre mode de numérotation existe, qui repose sur l’adressage processeur, appelé mode « BCM » (on prend en compte les chiffres après “GPIO” comme “GPIO 25”. On remarque qu’il existe des ports de différents types : des ports de puissance (5v et 3.3v), des ports généraux (GPIO), des ports PCM (Pulse-code Modulation) permettant une représentation numérique de l’analogique échantillonné (forme de sortie audio numérique), des ports UART (prend des octets de données et transmet les bits individuels de manière séquentielle), des ports I2C1 (permettent une communication bifilaire avec une variété de capteurs et de dispositifs externes), et des ports SPI (relient plusieurs dispositifs compatibles à un seul ensemble de broches en leur attribuant des broches de sélection de puce différentes). Nous avons décidé d’utiliser les ports généraux de la Raspberry pour notre montage (soit les ports GPIO), ainsi que le port 3.3v pour le bouton poussoir, par simplicité.
Pour utiliser les ports GPIO de la raspberry, il faut utiliser une librarie python. Il en existe plusieurs, mais la plus connue (celle pour laquelle il y a le plus d’exemple sur internet) est Rpi.GPIO. Ainsi, nous avons utilisé la librairie RPi.GPIO pour interagir avec notre montage via notre code Python. Nous devions ainsi indiquer au programme quel était le port de récupération du courant (input) et le port de sortie (envoi du courant). Pour se faire, nous avons utilisé la fonction setup, avec comme attributs GPIO.IN et GPIO.OUT pour indiquer respectivement le port d’entrée et de sortie de courant.
Ici, nous devions prendre en compte le fait qu’une entrée GPIO flotte entre 0 et 1 (fonction input). Par défaut dans la librairie, elle ne peut prendre que 1 ou 0 comme valeurs (True ou False). Aussi, lorsque l’utilisateur appuie sur le bouton, il y a plusieurs entrées qui arrivent dans la seconde qui suit (entre 0 et 1), qui sont arrondies à 1. Afin de ne pas confondre une entrée à 1 correspondant à l’appui sur le bouton par l’utilisateur et une entrée à 1 correspondant à un courant suivant l’appui sur le bouton, nous avons décidé qu’on considérait que l’entrée ne correspondait à un appui sur le bouton que s’il n’y avait pas d’autre courant reçu dans les 2 secondes précédant la réception du courant. Ainsi, si l’utilisateur appuie sur le bouton 2x en 2 secondes, voire plus, on ne considère pas que ce-dernier a appuyé.
Dès lors, il était important, particulièrement suite à ce que nous venons d’expliquer ci-dessus, de prévenir l’utilisateur lorsqu’il enregistre et lorsqu’il a fini d’enregistrer, c’est-à-dire si son appui sur le bouton a bien été pris en compte ou non. C’est pourquoi nous avons mis en place une Led, qui s’allume lorsque l’utilisateur appuie sur le bouton, et s’éteint lorsque l’on considère que l’utilisateur a rappuyé dessus. En d’autres termes, la Led prévient l’utilisateur quand l’enregistrement débute (quand on le lance) et quand l’enregistrement se termine (quand on l’arrête).
3. Le montage du dispositif de la led pour indiquer à l’utilisateur quand l’enregistrement est lancé
De la même manière que le bouton, la Led est branchée aux ports GPIO de la Raspberry Pi Zero W. Cependant, contrairement au bouton poussoir décrit ci-dessus, nous ne récupérons pas le courant (l’information) de la Led, mais on lui envoie du courant (de l’information) pour l’allumer ou l’éteindre. Alors que l’on utilisait la fonction input pour récupérer les informations issues du bouton poussoir ci-dessus, nous voulons envoyer des informations à la Led. Pour ce faire, nous utilisons la fonction output. Il suffit ensuite de mettre le pin en question (celui qui est lié à la Led) à True lorsqu’on veut l’allumer, et à False lorsqu’on veut l’éteindre. Ainsi, on allume ce-dernier lorsque l’on considère que le bouton poussoir a été appuyé, et on l’éteint lorsqu’on considère qu’il a été de nouveau allumé (à l’aide d’une variable isPressed que l’on a défini en amont, à qui l’on attribue l’opposé (not isPressed) dès lors que l’on considère que le bouton a été appuyé.
4. Explication détaillée du fonctionnement du montage final
Les parties 1, 2 et 3 ont ensuite été liées. En d’autres termes, lorsque l’utilisateur appuie sur le bouton, non seulement la Led s’allume, mais également l’enregistrement se lance. Lorsqu’il rappuie sur le bouton, la Led s’éteint et l’enregistrement s’arrête. Si la Led est allumé, c’est que l’enregistrement est nécessairement en route. Si cette-dernière n’est pas allumée, c’est que l’enregistrement ne l’est pas.
C. L’application
Pour l’application, le code est disponible sur le dépôt suivant: https://github.com/yac-ai/django_transcripen.git .Pour un développement rapide, le framework Django est utilisé, basé sur le langage de programmation Python. La raison de ce choix est dû au fait que nous avions déjà de l’expérience dessus. Et, vu qu’il fallait aller très vite, ce choix était plus sûr. Pour ce projet, on a créé un environnement virtuel; son avantage d’un environnement virtuel est l’isolation des environnements de développement avec des librairies installées différentes pour chaque projet. Ainsi, nous pouvons installer une certaine version de Python, différente de celle installée dans l’ordinateur et pour nos potentiels autres objets, et les librairies souhaitées. La création et l’activation se font par les commandes suivantes:
python -m venv /home/yacine/.virtualens/djangodev
#yacine étant le nom de votre utilisateur #cmd de création
source ~ /.virtualenvs/djangodev/bin/activate #cmd d’activation
Le framework possède un serveur Apache intégré, en phase de développement. Et l’avantage du serveur Apache est la possibilité de visualiser le fonctionnement du site web. Aussi, à la récupération du dépôt git, il faudra se positionner dans le répertoire transcripen_project et lancez la commande suivante qui va activer le serveur apache:
python manage.py runserver
Sommairement, le projet comprend ainsi, dans le dossier transcripen_project/transcripen, les vues qui permettent de traiter les données de chaque page( dans le fichier views.py), les urls qui sont reliés à ces vues (dans le fichier urls.py) et les templates des pages qui contiennent le code html de ces pages(dans le dossier templates).
Pour avoir plus d’informations sur le framework et son fonctionnement, vous pouvez voir référer au lien suivant: https://docs.djangoproject.com/fr/4.0/ . La documentation est très bien faite et facile à comprendre.

D. La transmission des fichiers audio de la raspberry à l’application
Notre projet Transcripen consiste en un stylo enregistreur qui communique avec une application sur l’ordinateur pour que cette dernière transcrive l’échange. Le stylo est un objet connecté qui doit par conséquent s’appuyer sur une transmission sans fil dont notre choix s’est porté sur le Wi-Fi. Il existe différents modes de mise en réseau en Wi-Fi. Pour Transcripen, nous avons opté pour le mode d’infrastructure. Ainsi, l’ordinateur sur lequel tourne l’application et le raspberry contenu dans le stylo sont connectés entre eux dans un réseau local via un point d’accès ou un routeur. Ainsi, nous avons nos deux équipements qui sont dans le même sous-réseau et qui peuvent communiquer facilement.
La norme 802.11 utilise des ondes électromagnétiques pour une liaison sans fil avec la couche physique qui définit la modulation des ondes radioélectriques et les caractéristiques de la signalisation pour la transmission de données, et la couche liaison de données qui définit l’interface entre le bus de la machine et la couche physique. La troisième couche, celle qui est responsable du transport des messages complets de bout en bout (soit de processus à processus) au travers du réseau est assurée ici par le protocole TCP.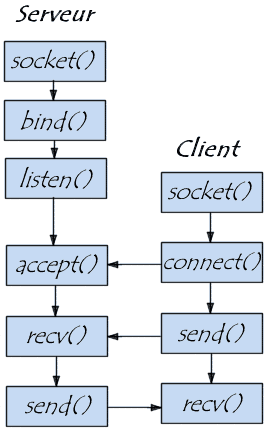
Pour permettre cette transmission, nous avons utilisé les sockets TCP. Concrètement, un socket représente l’association entre IP et Port. L’IP identifie la machine et le port une application. Dans notre projet, le serveur tourne dans le stylo et le client est intégré dans l’application. Ainsi, le serveur est activé à intervalle de temps régulier dans la raspberry pour permettre, dès qu’elle détecte le client de lancer la transmission. Dans notre cas, le serveur se charge d’envoyer l’audio et le client reçoit le fichier en plusieurs paquets de 1024 octets.
Ce choix est dû principalement à la facilité d’intégration et au fait que c’était une des compétences déjà acquises dans l’équipe.
E. Algorithme de transcription d’un fichier audio en fichier texte
L’algorithme est disponible sur le Github du projet, dans la rubrique: https://github.com/camillebrl/Transcripen/blob/main/application/transcription_text/algo_speech_recognition.py.
Nous avons créé une classe qui a pour attributs le chemin d’un fichier audio .wav ainsi que sa langue et qui renvoie le texte correspondant à la transcription du fichier audio en question. Cette classe effectue un « préprocessing » de l’audio d’entrée (calcul de la durée de l’audio, découpage en sous-audios de 10s), et applique à l’audio préprocessé l’algorithme de Speech Recognition développé par Google et accessible simplement via une API (incluse dans la librarie speech_recognition disponible sur Github https://github.com/Uberi/speech_recognition).
Nous utilisons pour cela plusieurs libraires, notamment Pydub, qui est une librairie permettant de manipuler un fichier audio simplement (ouverture de l’audio, augmentation / diminuaiton du volume de l’audio, segmentation de l’audio, calcul de la durée de l’audio, et toute autre manipulation possible sur un audio. La librairie est en open-source sur https://github.com/jiaaro/pydub). Pour utiliser pydub, il faut installer ffmpeg/avlib. nous utilisons aussi la librairie speech_recognition (https://github.com/Uberi/speech_recognition) qui effectue de la reconnaissance vocale via diverses APIs, en ligne et hors ligne, notamment CMU Sphinx, Google Cloud Speech, WIT.ai, Microsoft Azure Speech, Houndify, IBM Speech to Text, ou encore Snowboy Hotword Detection. Les différents réseaux ont été entraîné sur des audios dont la taille de dépasse pas les 50 secondes. Dès lors, nous avons découpé le fichier audio en sous-audios de 10s.
- Le découpage de l’audio
Pour découper l’audio en slots de 10s, on a tout d’abord récupéré la durée de l’audio à l’aide de la fonction duraction_seconds de Pydub. On divise ensuite la durée totale en n sous ensembles de 10 secondes. Pour ce faire, nous utilisons la fonction range de python (range(0, nombre total de secondes de l’audio, 10). On itère (for i) sur toutes les valeurs de cette liste, c’est-à-dire sur les secondes de l’audio. On coupe ensuite l’audio entre la seconde i et la seconde i + 10. Afin d’éviter qu’il y ait des coupures de mots qui gêneraient la transcription de chaque slot d’audio, on prend 1 seconde avant et 1 seconde après de l’audio (plus de détails dans la documentation de l’algorithme sur https://github.com/camillebrl/Transcripen/blob/main/application/transcription_text/algo_speech_recognition.py en lignes 49 à 55). Une fois le slot d’audio récupéré, on l’exporte.
2. L’application de l’algorithme sur les slots de 10 (exactement 11 à 12s d’audio)
Sur ce slot d’audio, on applique la fonction recognize_google (appel de l’API Google qui n’a pas de limite d’appel) sur le slot d’audio, et en définissant la langue. On a en retour un string correspondant à la transcription de l’audio du slot.
3. La concaténation finale du résultat
L’algorithme est donc appliqué sur chaque slot d’audio (on supprime le .wav du slot à chaque fois que l’on a obtenu la transcription de l’audio). On ajoute les transcriptions de chaque slot dans un string général (variable de la classe final_result). On obtient ensuite la transcription de l’audio tout entier.
III/ Résultats
La démonstration présente des résultats concluants sur de nombreux point :
- Bien qu’étant de volume conséquent, l’objet présenté est bien portable, auto-alimenté et communique sans fil.
- L’enregistrement de l’audio se déroule sans réels problèmes, la qualité de l’enregistrement est très satisfaisante pour une distance à l’objet d’environ 50 cm. Cela est tout à fait cohérent avec le contexte d’un échange entre 2 personnes.
- L’application reçoit bien le fichier audio, le transcrit et l’affiche sur l’application Web. La transcription est assez satisfaisante, bien que tous les mots ne soient pas réellement transcrits parfaitement. L’esprit et la forme globale de l’échange est bien retranscrit par la solution est ceci était l’objectif principal
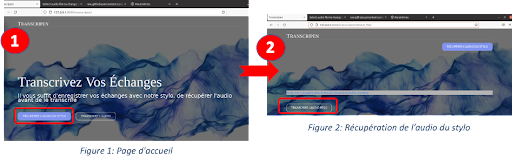
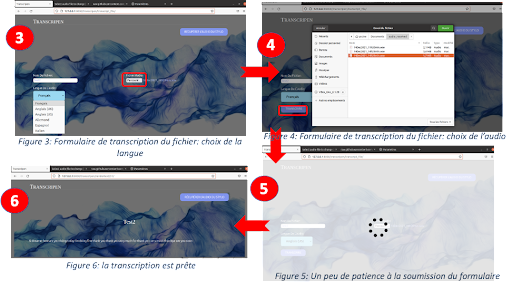
IV/ Perspectives
- Automatisation du lancement de nos algorithmes lorsque la Raspberry boote: Nous n’avons pas configuré une exécution du script de manière automatique par manque de temps. Si nous avions eu une semaine supplémentaire (soit un sprint de plus), nous aurions pu mettre cela en place. Dès lors, nous étions obligé de lancer les commandes “python3 final_algo.py” en se connectant en SSH à la Raspberry afin de le faire tourner. Nous aurions pu effectuer une configuration du démarrage de la Raspberry afin que celle-ci lance automatiquement notre algorithme. Pour ce faire, nous aurions pu définir un contrab qui permet, après chaque démarrage, d’exécuter automatiquement un script, à l’aide de la ligne “@reboot /home/user/final_algo.sh”.
- Miniaturisation: La principale amélioration possible serait de réduire considérablement la taille de nos composants. Dans un premier temps la carte Raspberry Pi Zero pourrait être remplacée au profit d’une carte plus petite intégrant uniquement les ports (seulement 4 port de donné, un port d’alimentation) dont nous avons besoins et un circuit imprimé ne contenant uniquement nos algorithmes utilisé pour le service rendu. Du côté de la batterie sa taille pourrait être diminuée également en réduisant sa capacité. Des tests devront être effectués sur les performances énergétiques des différents composants afin de calculer précisément la capacité nécessaire de notre batterie, pour information la Raspberry Pi Zero W requiert 5V pour environ 300 mA. En conclusion, plus la taille des composants se réduit, plus leur prix de production et de développement augmente.
- Ajout d’un bouton pour surligner les moments importants de l’audio: En plus de transcrire l’audio en texte, nous aurions pu
- 2 algorithmes tournent : un qui transcrit le tout, un autre juste le moment indiqué, et on fait une recherche dans le document de là où se situe le paragraphe en question, et on y met un effet dessus
- Ajout d’un algorithme de différenciation des interlocuteurs : il existe un ensemble d’algorithmes disponibles (notamment de Google) qui permettent d’effectuer une différenciation d’interlocuteurs d’un audio. Nous aurions pu l’ajouter à notre projet si nous avions eu davantage de temps. Cependant, puisque nous travaillons sur des slots d’audios et puisque les algorithmes sont entraînés sur des audios de courte durée, nous ne savons pas comment nous aurions pu traiter cela. De nombreuses recherches ont été effectuées sur le sujet (sur de longs audios) que nous aurions pu étudier, si nous avions eu davantage de temps.
- Possibilité de configurer le cloud: le choix du wifi reste un bon choix. Mais on pourrait considérer le Cloud qui permettrait de stocker les audios et de récupérer tous les audios enregistrés dans l’application web.
