
Malgré le développement de la dactylographie, l’écriture manuscrite conserve une place importante dans notre quotidien : elle est toujours enseignée aux enfants et reste un moyen naturel pour fixer la pensée. Cependant, l’écriture manuscrite présente des défauts : elle reste figée sur un support matériel, difficilement duplicable, volumineux et par conséquent plus difficile à transmettre. Une solution pour concilier les avantages du manuscrit avec la flexibilité du numérique est de concevoir un stylo pouvant numériser et stocker l’information et permettre son partage sur plusieurs appareils. C’est le cas du stylo fabriqué par STABILO DigiVision, le Digipen. Celui-ci enregistre, grâce à plusieurs capteurs de mouvements, les données du mouvement de la main lors de l’écriture d’une lettre. Afin de rendre ce stylo utilisable, il est nécessaire de le coupler à un algorithme pouvant reconnaître des caractères manuscrits à partir de ces données issues de capteurs.
L’objectif du projet TEXT-ML, réalisé dans le cadre du projet CODEVSI, est de développer cet algorithme d’apprentissage. L’algorithme prend en entrée les données inertielles correspondantes aux caractères manuscrits et fournit en sortie les caractères identifiés. Il doit être capable de reconnaître toutes les lettres de l’alphabet latin en minuscule et en majuscule dans une configuration qui s’approche d’un cas d’utilisation réel.
L’équipe projet est composée de 4 étudiants de FISE-1A : Adrien Faye, Frédéric Lin, Léo Stengel, Touzi Ali et est encadrée par Charlotte Langlais et Gulia Lioi.
Réalisation.
La réalisation du produit s’est faite en plusieurs parties.
Tout d’abord, nous avons récupéré un ensemble de données, ou dataset, créé par l’équipe de recherche STABILO Digipen et disponible en ligne. Cet ensemble est constitué de 31000 échantillons de données directement issues des capteurs intégrés au stylo, chacun étant associé à la lettre correspondante. Ces données brutes sont difficilement manipulables et assez peu adaptées à l’entraînement des modèles. Il a donc été nécessaire de préparer les données avant l’étape d’entraînement des modèles, c’est l’étape dite de preprocessing. Celle-ci consiste à formater et normaliser l’ensemble du dataset, puis à le séparer en trois ensembles distincts : entraînement, validation et test.
Vient ensuite l’étape de l’entraînement des modèles avec notre jeu de données préparé. Pour cela, nous implémentons les modèles sur Python en passant en paramètre le jeu de données que nous avons formaté lors de l’étape précédente à l’algorithme du modèle.
Finalement, une fois l’entraînement d’un modèle achevé, nous comparons nos résultats avec ceux de l’état de l’art, qui servent de référence dans ce projet. Les premiers résultats sont souvent assez faibles, il faut donc modifier les paramètres des modèles afin d’améliorer les résultats. Cela constitue la troisième étape de ce projet : l’optimisation des modèles. Plusieurs paramètres sont testés et, de manière empirique, nous déterminons les paramètres les plus adaptés pour l’entraînement des modèles.
![]()
En parallèle de ce processus se déroule la conception de l’interface graphique permettant l’utilisation des modèles entraînés de manière intuitive et accessible à des utilisateurs externes.
Présentation du produit.
Le produit fini se présente sous la forme d’un programme Python qui, une fois exécuté, ouvre une interface graphique. L’archive du projet est disponible au téléchargement sur : https://gitlab.imt-atlantique.fr/g20lioi/text-ml-2022.
L’interface graphique se présente comme ci-dessous :
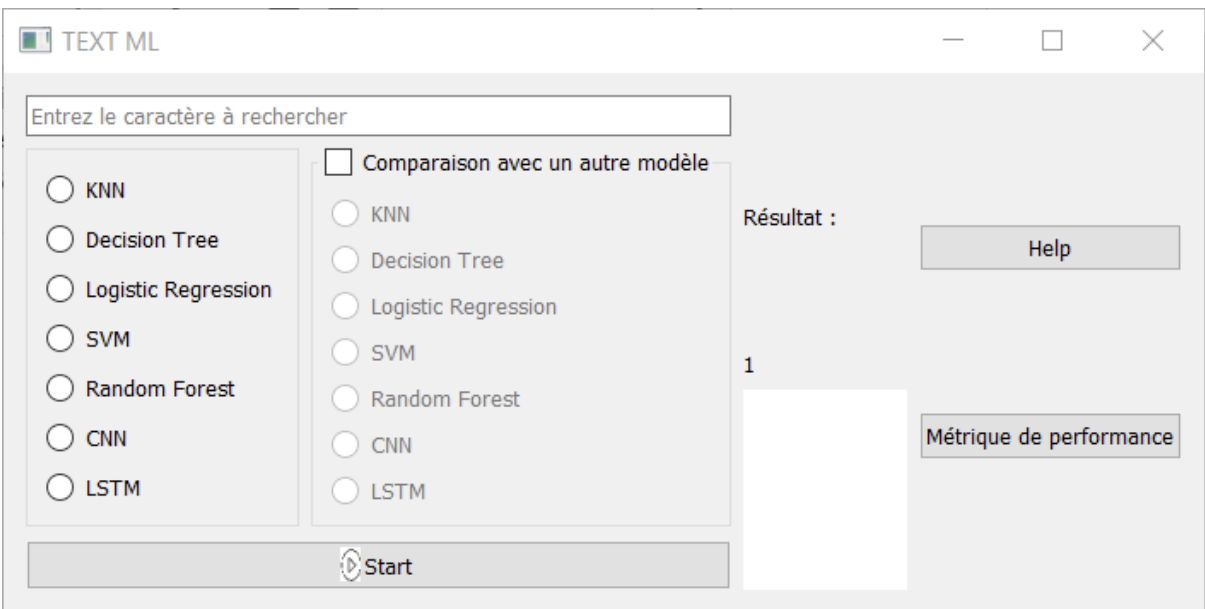
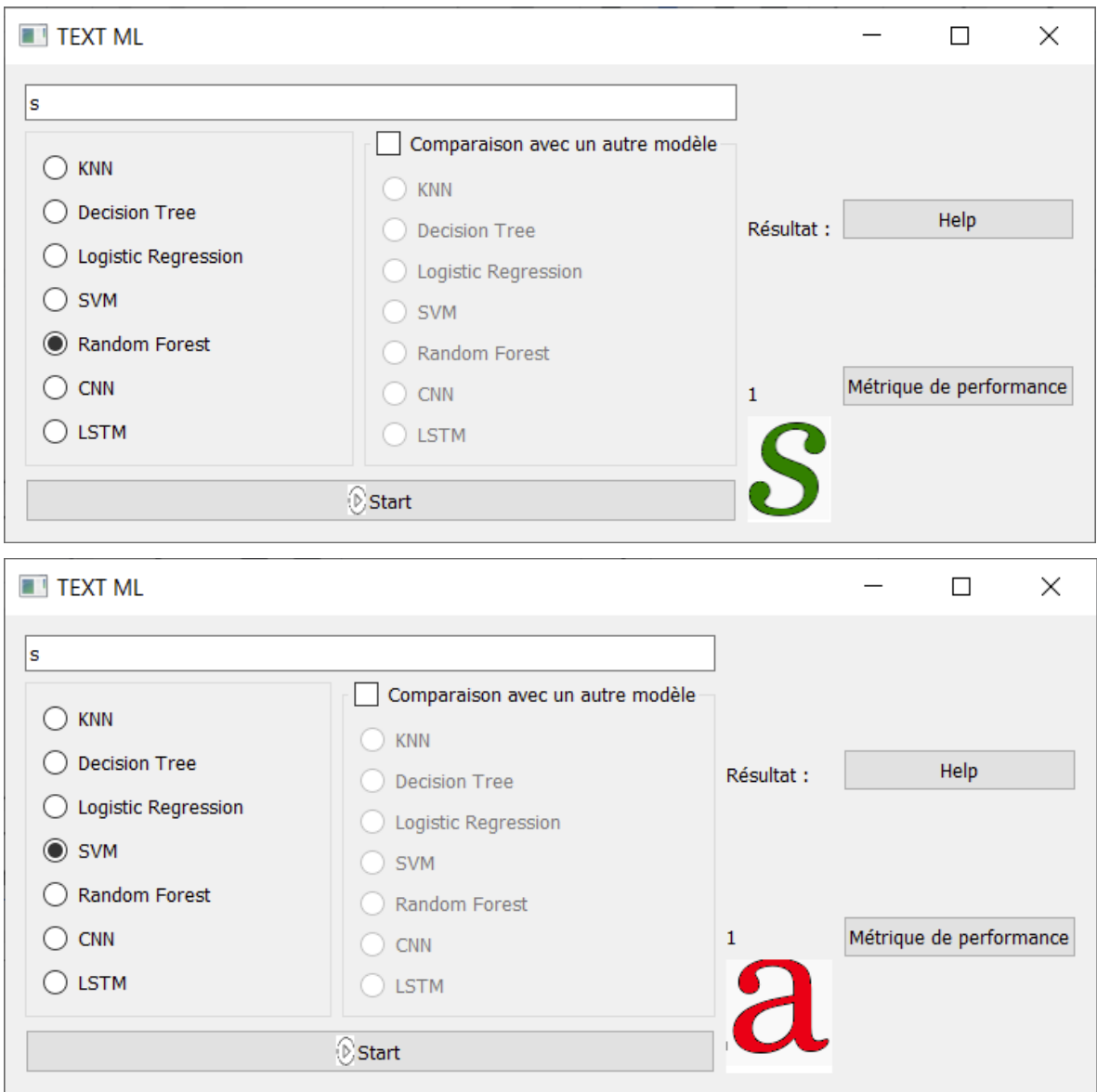
L’utilisateur entre un caractère, choisit un modèle puis appuie sur le bouton Start pour démarrer la reconnaissance d’un caractère manuscrit : ce caractère est choisi parmi tous les caractères dans le dataset de test qui correspondent au caractère entré par l’utilisateur. La prédiction du modèle est alors affichée en verte si celle-ci est correcte sinon elle est affichée en rouge comme ci-dessous :
Pour des utilisateurs plus expérimentés dans le domaine, une page métrique de performance a été ajoutée à l’interface et ceux-ci peuvent retrouver les évolutions des performances selon certains paramètres pour chacun des modèles et les résultats de performances des différents modèles.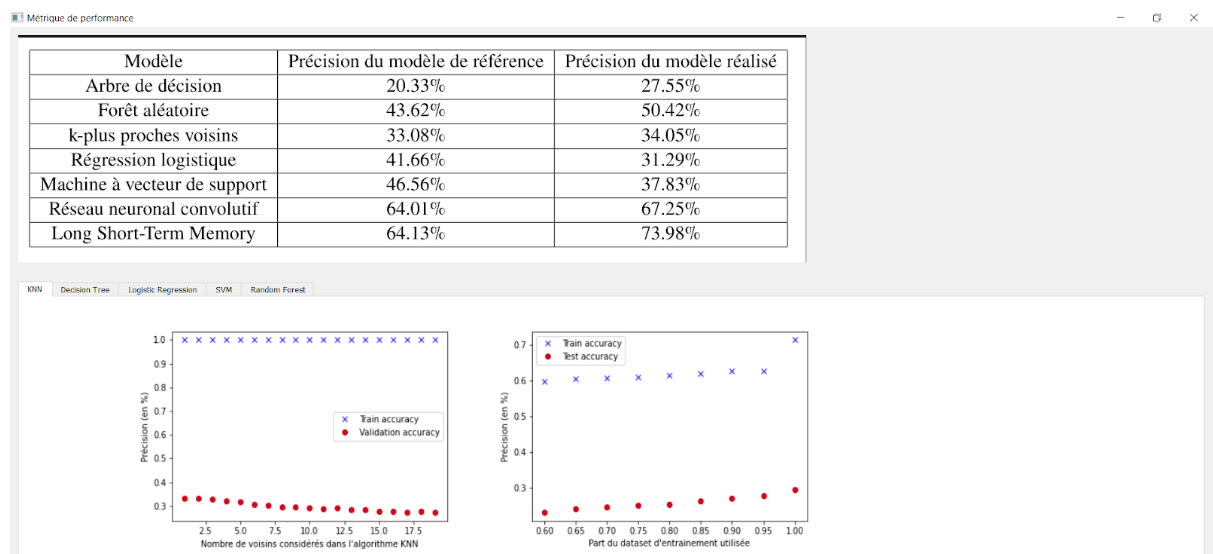
Perspectives d’évolutions du projet.
L’équipe du projet propose une variété de modèles différents, dont certains obtiennent une meilleure précision que l’état de l’art, et ces modèles peuvent être déployés sur un stylo muni de capteurs inertiels. Il semble alors intéressant d’améliorer les modèles moins performants. Mais, plus important encore, implémenter une transmission directe entre un stylo et l’interface graphique sera nécessaire par la suite pour s’approcher de la numérisation de l’écriture manuscrite.
Par ailleurs, étendre ce type de reconnaissance à tout type de caractères, voire à des tracés, paraît inévitable pour la numérisation de textes manuscrits complets. Pour parvenir à un stylo dont nous pourrions totalement numériser les mouvements, certains obstacles restent à franchir, mais une numérisation des textes manuscrits semble être dans un futur proche.
